大模型使用过程中针对模型微调与预训练的经验总结记录
Pre-Training
什么是Pre-Training
先收集大量不需要human labeling 的文本
在这些文本上做language modeling 的预训练任务
这样的话模型就能从大量的unlabeled data里面掌握一个fundamental language knowledge,这个模型也被称作基座模型
Pre-Training有哪些问题
数据收集
目标:收集大量unlabeled text data
通用数据:收集各种各样的网页、书籍以及对话数据等
专业领域:收集多语言文本、来自专业领域的专业文本,比如论文网站arxiv,代码网站github
文本质量越高越好,小模型在高质量文本上的训练效果也可以媲美大模型
Gunasekar et al., Textbooks Are All You Need. 2023.
可以看一下现如今大模型的数据来源组成
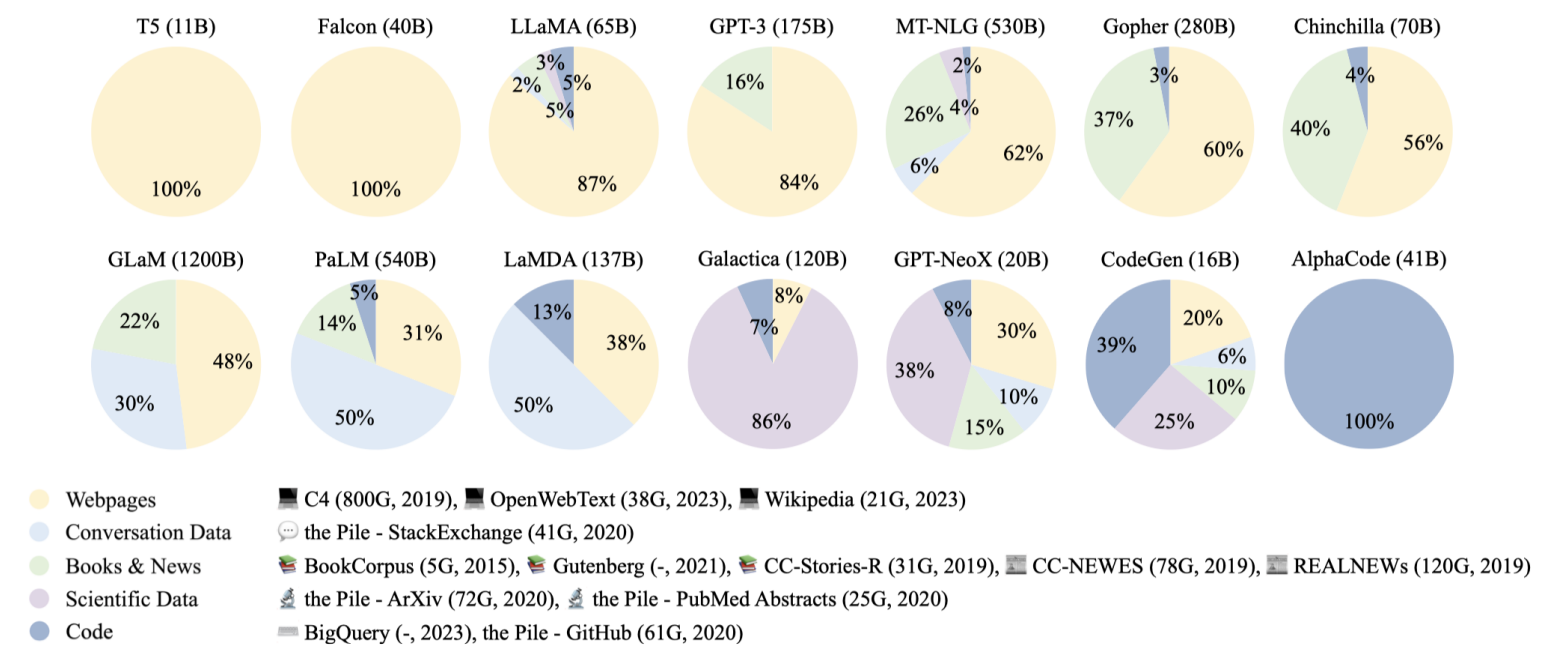
Image from: Zhao, Wayne Xin, et al. “A survey of large language models.” arXiv preprint arXiv:2303.18223 (2023)
数据预处理
一般的数据预处理流程:
从各种各样的来源收集原始语料库 raw corpus;
数据清洗
删除:主要思路是基于统计特点做一些过滤,去除一些干扰字符, 主要方法包括:
a. 语言过滤
b. 关键字过滤
c. 统计过滤
d. 度量过滤
最终实现剔除非目标任务语言、丢弃低perplexity数据、删去标点/符号过多或过长过短的句子、删除具有某些特定词汇(如html标签、链接、脏话、敏感词)的句子
去重:
a. 包含大量重复词汇或短语的句子可以删掉;(sentence-level)
b. 重复率(词/n-grams共现)过高的段落可以删掉;(document-level)
c. 删除训练集中可能与测试集相关度过高的内容。(set-level)
隐私保护:通过关键词等方式剔除用户隐私信息(姓名、地址、电话等)
分词:清洗语料之后便可以进行分词,要么直接使用GPT-2等现成的分词器,要么对训练语料构建基于SentencePiece、Byte Pair Encoding等算法的分词方式,最终实现词与ID的一一映射。
推荐使用大语言模型数据预处理工具data-juicer
数据安排:
a. 数据混合:不同来源的数据如何送入训练
b. 数据进阶:每种数据源下数据进入训练的顺序。例如由简到难,逐渐学会复杂的问题
模型架构
如何选择合适的模型
纯自监督预训练:对只有解码器的模型进行预训练的效果最好
多任务微调预训练:使用masked 语言建模预训练的编码器解码器表现最佳。
长文本建模
- window attention: 无论input有多少,可以把attention值分配给最临近的 L个 attention,实现一个有带窗口限制的最近临的attention
- 在transformer做计算的过程中有很大量的attention score被分配最初的几个token,这种token叫做sink tokens, 也就是说他接收到了最大量的一个attention weights, 可以结合window attention, 既关注到我最近的几个邻居token,又持续关注着最开始的那几个token
模型训练
训练策略
3D parallelism
数据并行:这涉及同时在多个 GPU 或 TPU 上训练模型,每个 GPU 或 TPU 处理数据的不同部分。
管道并行:当模型在一个gpu上都放不下时,可以将模型的参数分割到多个设备上,从而允许它们同时更新。
张量并行:张量按照行或列的方式切分,分开计算。
混合精度训练
我们将模型的weights, activations, gradients等等信息从32位的浮点数转换为16位
Fine-tuning
什么是Fine-tuning
得到基座基础之后,假如想提高某一个具体的任务,比如想做question answering或者dialogue system或者information extraction等 ,那么可以用相应的supervised learning data去做第二阶段的fine-tuning, 这样的话相当于基座模型在子任务的基础上又做了一个进一步的训练。
对比pre-training与fine-tuning:
- pre-training 阶段的data规模非常大,因为它是unlable data, 来源可以是网上收集的文本;
- fine-tuning dataset规模小得多,它来源于人为或者高精度的模型去标注的
有监督微调(SFT)
对比两组对话
| 问题 | 回答 |
|---|---|
| 无法登录账户应该怎么做? | 尝试使用 “忘记密码 “选项重置密码。 |
| 无法登录账户应该怎么做? | 很遗憾您在登录时遇到困难。您可以尝试使用登录页面上的’忘记密码’选项重新设置密码。 |
可以看出第二组问答更符合带有同理心的服务场景。
所以对 LLM 进行微调是有必要的,主要原因如下:
获得与业务准则相匹配的答案。
提供新的特定/私人数据,这些数据在训练步骤中并未公开,以便 LLM 模型适应特定知识库。
教会 LLM 回答新的(未见的)问题;
利用 Trainer class 实现 Finetuning
1 | from transformers import TextDataset,DataCollatorForLanguageModeling |
利用 trl 模块的 SFTTrainer class 实现 Finetuning
1 | from transformers import AutoModelForCausalLMfrom datasets import load dataset |
使用LoRA 微调 Llama 2
量化配置
在使用 LoRA(低秩适应)训练机器学习模型的背景下,有几个参数发挥作用。以下是每个内容的简化解释:
LoRA 特定参数
**Dropout Rate (lora_dropout)**:这是训练期间每个神经元的输出设置为零的概率,用于防止过度拟合。
Rank (r): Rank 本质上是衡量原始权重矩阵如何分解为更简单、更小的矩阵的指标。这减少了计算要求和内存消耗。较低的排名使模型更快,但可能会牺牲性能。最初的 LoRA 论文建议从 8 开始,但对于 QLoRA,需要 64 开始。
lora_alpha:此参数控制低秩近似的缩放。这就像原始模型和低阶近似之间的平衡行为。较高的值可能会使近似值在微调过程中影响更大,从而影响性能和计算成本。一般是r的2倍。
通过调整这些参数,尤其是 lora_alpha 和 r,可以观察模型的性能和资源消耗变化,找到特定任务的最佳设置。
1 | import torch |
可以看到已经有模型保存了
一些经典开源语料数据集
- GPT-4all 数据集: GPT-4all(成对,英文,400k 条目)–由 OIG、P3 和 Stackoverflow 的一些子集组合而成,涵盖一般 QA 和定制的创意问题。
- RedPajama-Data-1T:RedPajama(PT,主要为英语,1.2T 词条,5TB)–完全开放的预训练数据集,遵循 LLaMA 的方法。
- OASST1: OpenAssistant(配对、对话、多语言、66,497 个对话树)–一个大型、人工编写、人工标注的高质量对话数据集,旨在改进 LLM 响应。
- databricks-dolly-15k: Dolly2.0(成对,英语,1.5 万+条目)–一个由人工撰写的提示和回复数据集,以问题解答和总结等任务为特色。
- AlpacaDataCleaned: 一些 Alpaca/ LLaMA-like 模型(成对,英文) - Alpaca、GPT_LLM 和 GPTeacher 的清理版本。
- GPT-4-LLM 数据集: 一些类似 Alpaca 的模型(Pairs、RLHF、英语、汉语,52K 条英语和汉语条目,9K 条非自然指令条目)- 由 GPT-4 和其他 LLM 生成的数据集,用于改进 Pairs 和 RLHF,包括指令和比较数据。
- GPTeacher:(Pairs,英语,20K 条目)- 由 GPT-4 生成的目标数据集,包括来自 Alpaca 的种子任务和角色扮演等新任务。
- Alpaca 数据: Alpaca, ChatGLM-fine-tune-LoRA, Koala (Dialog, Pairs, English, 52K entries, 21.4MB) - 由 text-davinci-003 生成的数据集,用于增强语言模型遵循人类指令的能力。