本文就chain_type的选择以及promt优化使用以及效果做实验介绍
关于chain_type的选择
这里引用 对比结果 看一下不同chain_type 的效果。 我在本地只有refine和stuff成功了,另外两种使用时遇到了奇奇怪怪的问题,起初以为是中文的问题,但后来验证下来也不是这个原因,具体使用成功的案例还希望有大佬能提供思路一起学习呐。
stuff
Stuff 是一种简单的方法,它会检索所有相关的文档块,并将其作为一个整体放入提示中,然后发送给LLM 生成响应。
1 | from langchain.chains import RetrievalQA |
它能有效地将从向量存储中获取的所有相关块填充到 LLM 模型的上下文中作为提示。这样就能根据用户的查询生成响应。
当上下文较小,需要精确回答问题时,使用 stuff 会更清晰明了。
Map Reduce
Map Reduce 链首先对每个文档单独应用 LLM 链(Map 步骤),将链输出视为新文档。然后,它将所有新文档传递给单独的合并文档链,以获得单一输出(Reduce 步骤)。它可以选择先压缩或折叠映射文档,以确保它们适合合并文档链(通常会将它们传递给 LLM)。如有必要,压缩步骤会递归执行。
1 | from langchain.chains import RetrievalQA |
对于相同的查询,我们在使用 Map_reduce 链类型时得到了不同的响应,因为它在每个阶段都进行了汇总,然后才将其传递到最后阶段,因此对于需要根据汇总回答的文档块数量较多的大型场景,这种链可能是一个很好的用例。
Map Re-rank
映射重排会对对每个文档运行初始提示,不仅尝试完成回答,还为其答案的确定程度打分。得分最高的回答将被返回。
1 | from langchain.chains import RetrievalQA |
从上面的回复中我们可以看到,生成的答案是基于 vectorstore 中排名靠前的内容块摘要,然后将其传递给 LLM 来生成回复。它可以有效地用于长上下文场景,而且 Top K 较大,文档中可能包含多个主题相同的块。
本地部署进阶优化
输出语言
promt优化
这里给出三种优化方式:
- 直接调用model.chat时在搜索相关文本后将所有文档作为提示一遍输入给大模型;
1 | from langchain.vectorstores.chroma import Chroma |
回答效果如下:


调用langchain进行问答,对问题加提示词实现优化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55from langchain.vectorstores.chroma import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.llms.chatglm import ChatGLM
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
persist_directory = 'vector_zhenhuanzhuan_32' # 指定向量库文件夹位置
model_name = "shibing624/text2vec-base-chinese" # 指定加载embeddding模型
model_kwargs = {'device': 'cuda:0'}
encode_kwargs = {'normalize_embeddings': False}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
db = Chroma(embedding_function=embeddings, persist_directory=persist_directory) # 加载之前创建的向量库文件里的向量数据
llm = ChatGLM( # 通过api调用大模型
endpoint_url='http://127.0.0.1:8000',
max_token=2000,
top_p=0.7
)
retriever = db.as_retriever()
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, answer I don't know.
{context}
Question: {question}
Answer in Chinese:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT,"verbose":True}
qa = RetrievalQA.from_chain_type( # 启用问答模式开始聊天
llm=llm,
retriever = retriever,
#chain_type_kwargs=chain_type_kwargs)
chain_type= "stuff")
while True:
question = input("请提问: ")
if question == "quit": ### 键入 quit 终止对话
print("已关闭对话")
break
else:
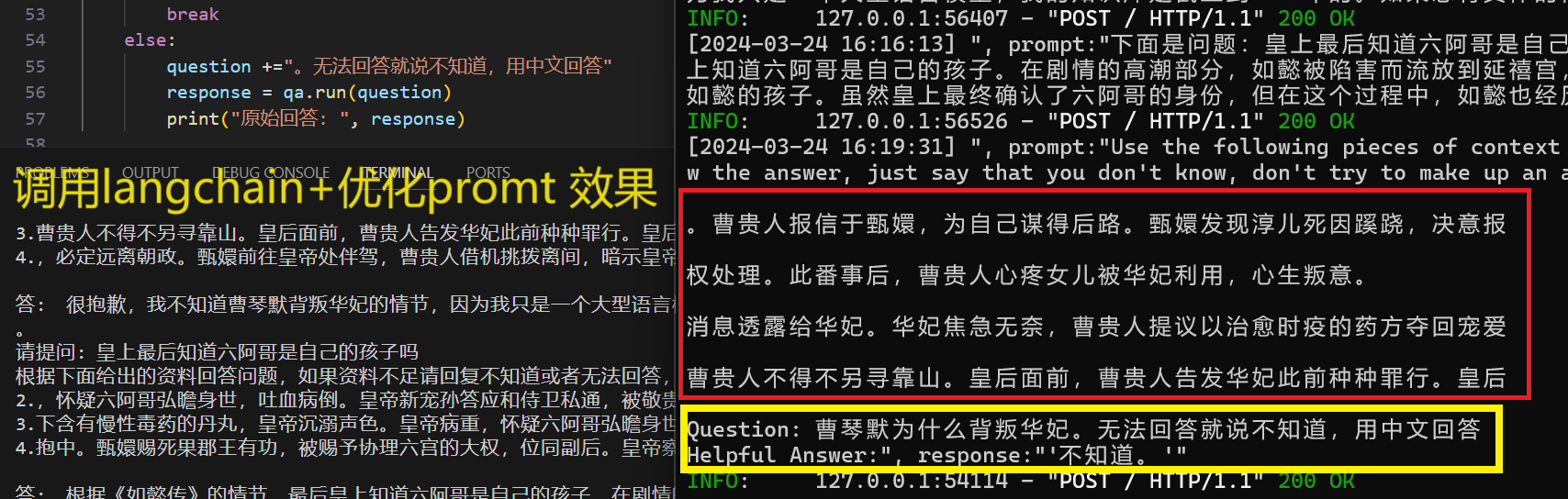
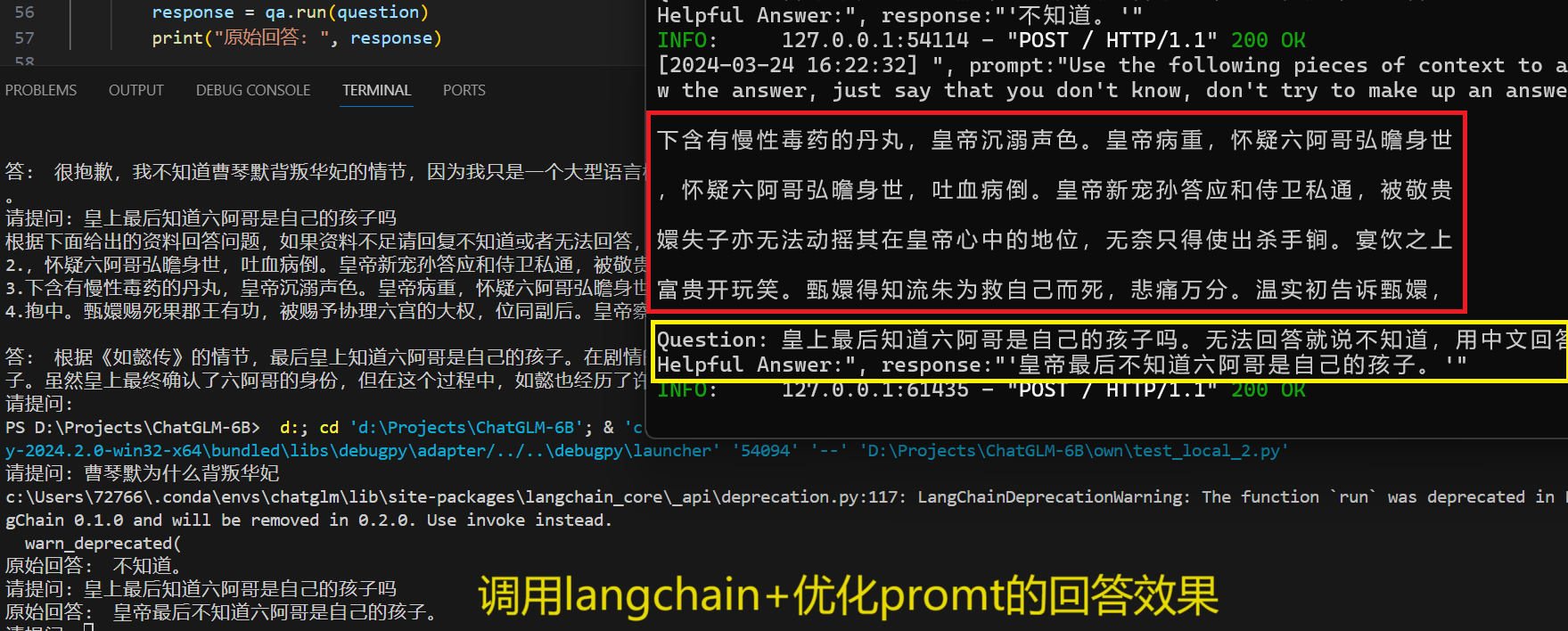
question +="。无法回答就说不知道,用中文回答"
response = qa.run(question)
print("原始回答: ", response)回答效果如下:
![]()
![屏幕截图 2024-03-24 162301]()
调用promt模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55from langchain.vectorstores.chroma import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.llms.chatglm import ChatGLM
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
persist_directory = 'vector_zhenhuanzhuan_32' # 指定向量库文件夹位置
model_name = "shibing624/text2vec-base-chinese" # 指定加载embeddding模型
model_kwargs = {'device': 'cuda:0'}
encode_kwargs = {'normalize_embeddings': False}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
db = Chroma(embedding_function=embeddings, persist_directory=persist_directory) # 加载之前创建的向量库文件里的向量数据
llm = ChatGLM( # 通过api调用大模型
endpoint_url='http://127.0.0.1:8000',
max_token=2000,
top_p=0.7
)
retriever = db.as_retriever()
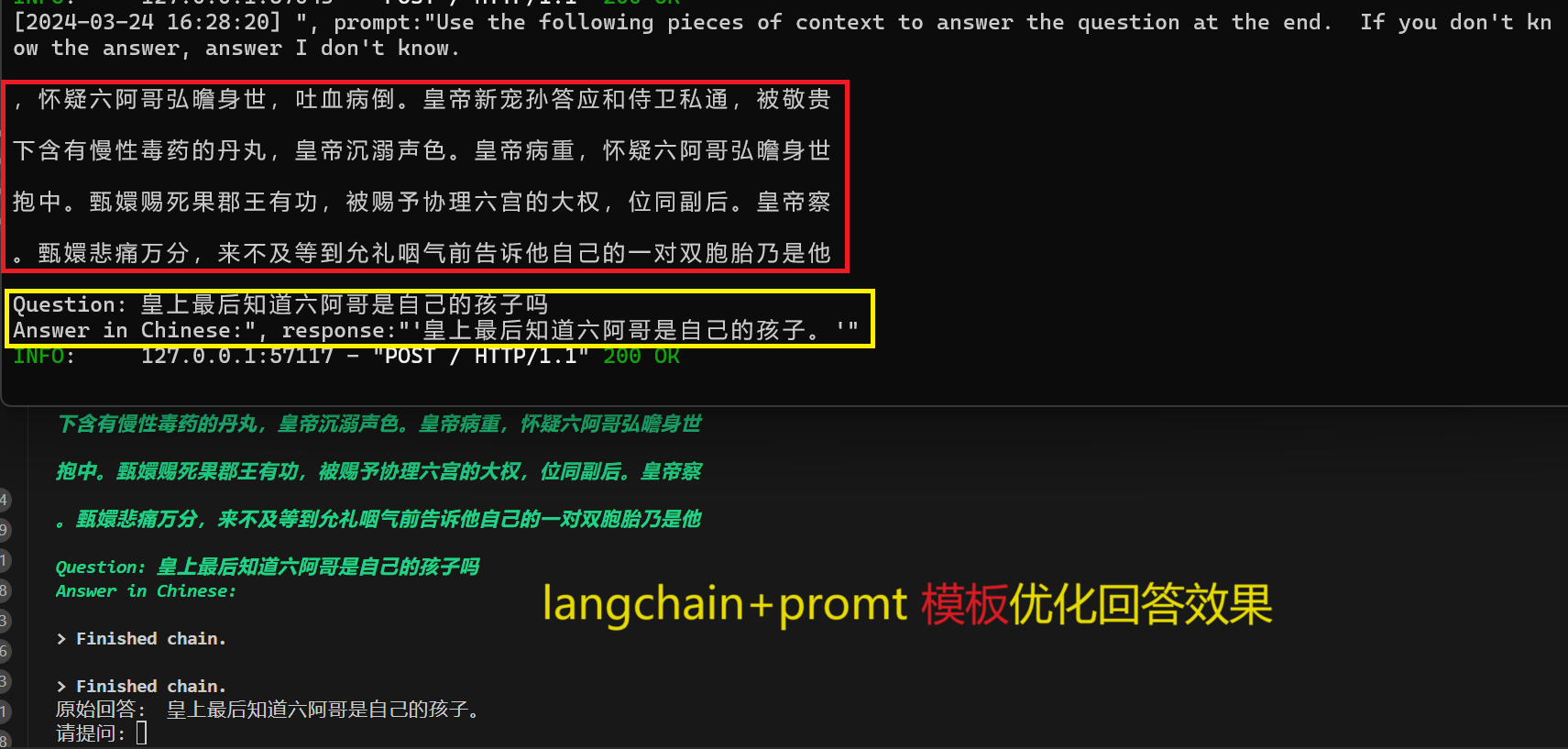
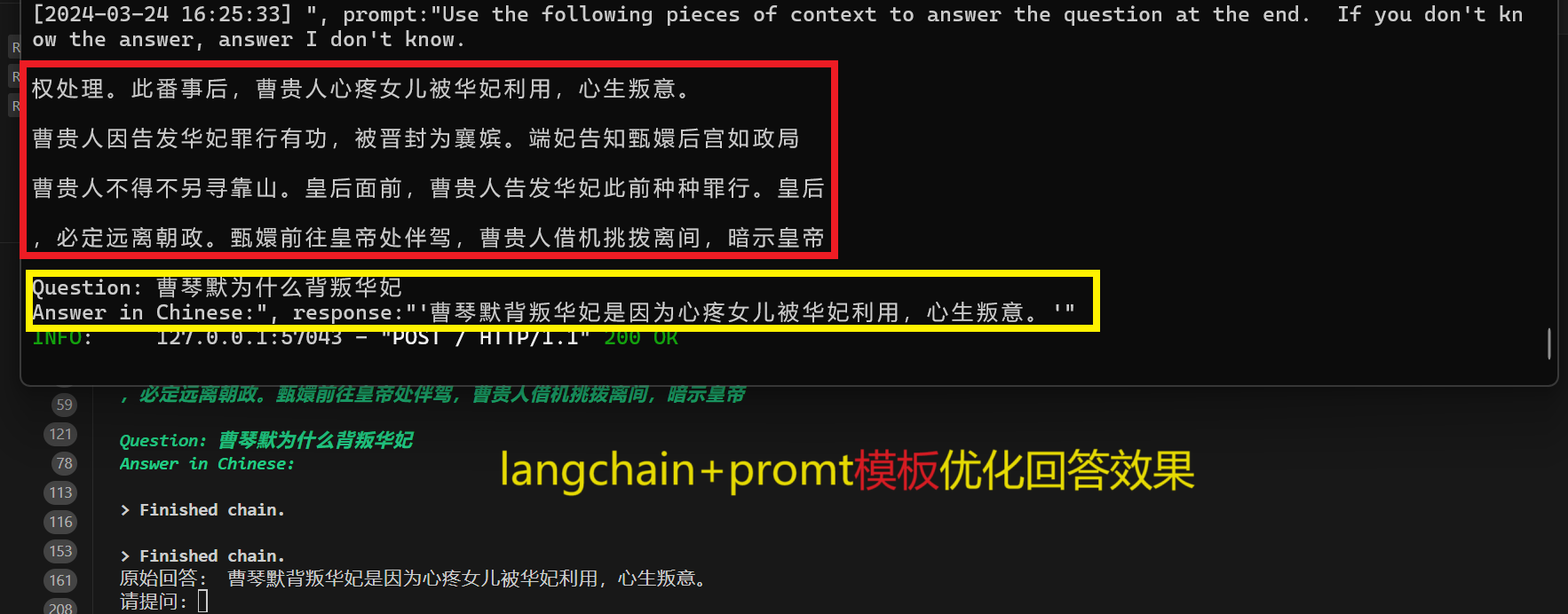
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, answer I don't know.
{context}
Question: {question}
Answer in Chinese:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT,"verbose":True}
qa = RetrievalQA.from_chain_type( # 启用问答模式开始聊天
llm=llm,
retriever = retriever,
chain_type_kwargs=chain_type_kwargs)
while True:
question = input("请提问: ")
if question == "quit": ### 键入 quit 终止对话
print("已关闭对话")
break
else:
response = qa.run(question)
print("原始回答: ", response)回答效果如下:
![]()
![屏幕截图 2024-03-24 162619]()
总结:
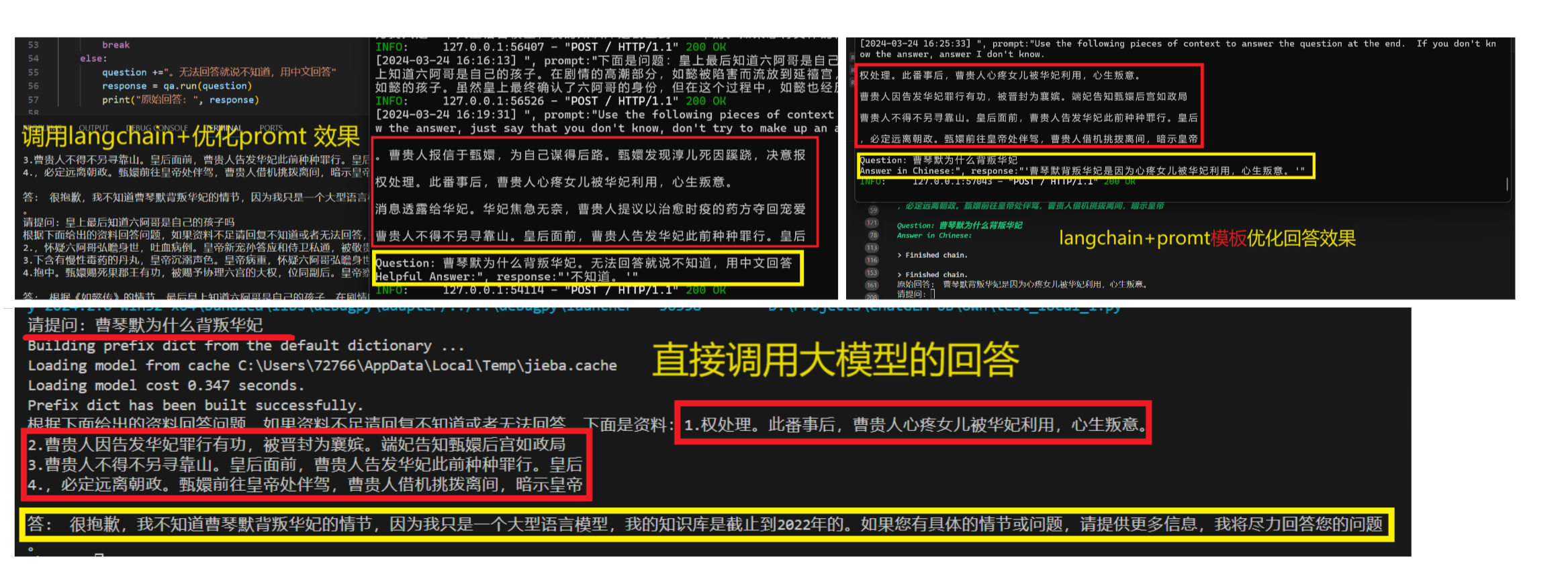
不变更输入的情况下,不同promt对搜索相似文本返回的匹配文档时一致的,除非变动输入,匹配结果会不同;
用promt模板的回答效果看起来要更好一些;