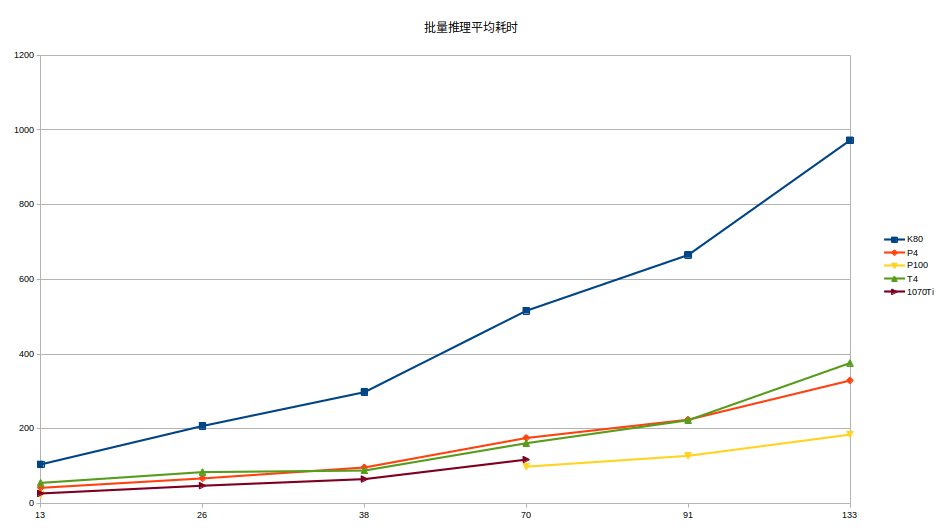
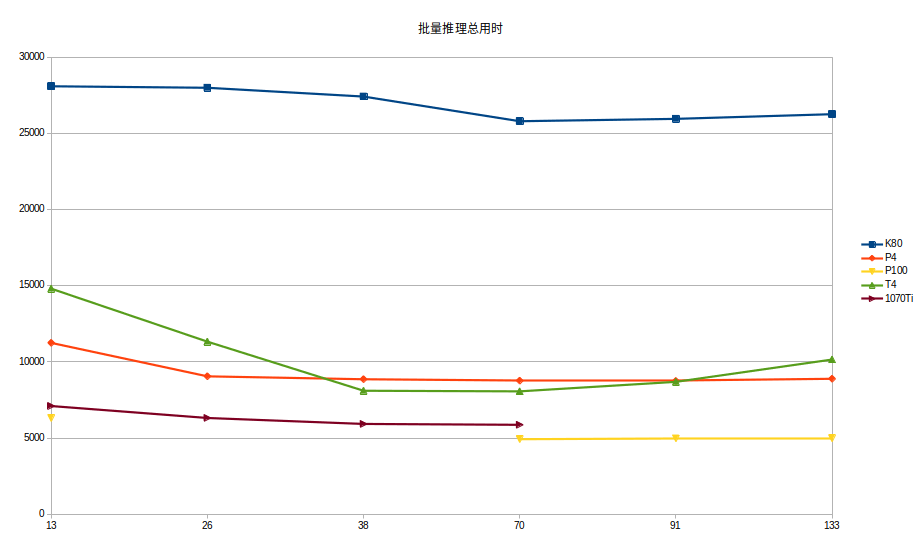
继续在colab上成功安装并配置好TensorRT, 接着我进行了针对几种不同显卡的测试,统计不同显卡(Tesla K80 Tesla P4 Tesla P100 Tesla T4)的批量测试耗时结果,大家可以根据最终的检测结果看出显卡对耗时的影响程度究竟有多大。
利用Google Colab成功测试TensorRT指南一
利用Google Colab成功测试TensorRT指南二
分配得到的环境
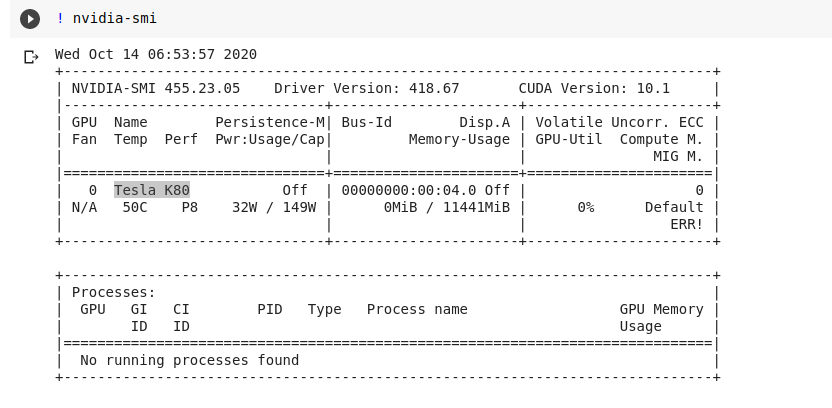
Tesla K80
![Tesla K80]()
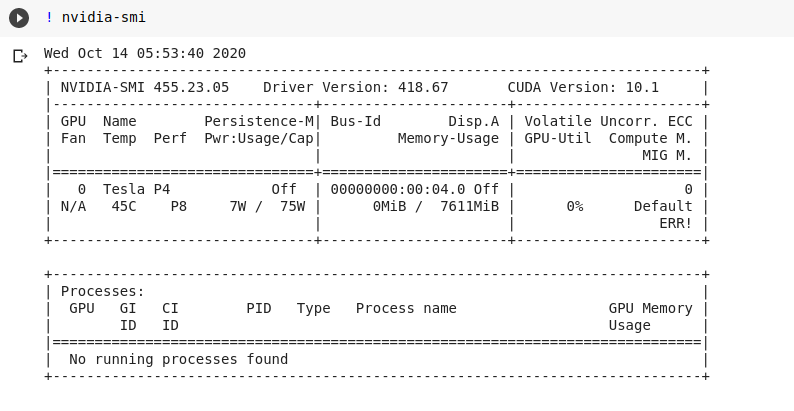
Tesla P4
![Tesla P4]()
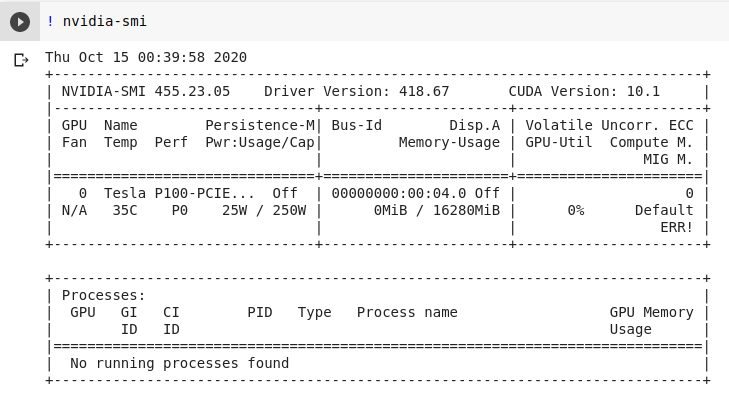
Tesla P100
![Tesla P100]()
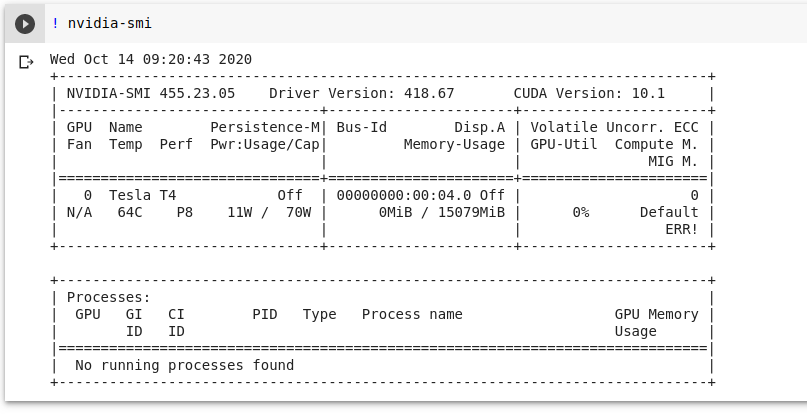
Tesla T4
![Tesla T4]()
批量测试结果
| 批量推理结果 |
| Image size(8k×40k), 预测裁剪小图size(300×300),w方向:8000/300=26,h方向:40000/300= 133,裁剪生成的小图有:26×133 = 3458张 |
|
Tesla K80 |
Tesla P4 |
Tesla P100 |
Tesla T4 |
| batch size |
avg time(ms) |
tol time(ms) |
avg time(ms) |
tol time(ms) |
avg time(ms) |
tol time(ms) |
avg time(ms) |
tol time(ms) |
| 13 |
104.39 |
28083 |
41.78 |
11241 |
23.42 |
6302 |
55.01 |
14799 |
| 26 |
207.29 |
27985 |
67 |
9046 |
|
|
83.85 |
11321 |
| 38 |
297.91 |
27408 |
96.25 |
8855 |
|
|
88.05 |
8101 |
| 70 |
515.76 |
25788 |
175.18 |
8759 |
98.42 |
4921 |
161.22 |
8061 |
| 91 |
665.23 |
25944 |
224.12 |
8741 |
127.46 |
4971 |
222.69 |
8685 |
| 133 |
972.25 |
26251 |
329.07 |
8885 |
184.25 |
4975 |
375.88 |
10149 |
![]()
![]()
结论:
1.就目前的测试结果来看,不同显卡的加速耗时是有挺大区别的,并且与batch的大小有关,所以要获取最优的时间,需要尝试不同的batch size;
2.对于云计算的环境,计算时长比本地还是有些差距,究其原因还需要思考,是否更优的显卡能获取更好的测试结果,只能再多测以结果为准了。