近期一直在研究TensorRT的加速原理,对于层融合起先一直不理解,现在总算是知道加速的原理了,所以就把自己理解到的结合网上找到的一些资料进行整理汇总,最后我贴出自己整写的一个关于TensorRT加速原理的PPT,有需要的同学可以自己下载下来看看
TensorRT简介
TensorRT是NVIDIA 推出的基于CUDA和cudnn的进行高性能推理(Inference)加速引擎。
●曾用名:GPU Inference Engine(GIE)
●Tensor:表示数据流动以张量的形式
●RT:Runtime
训练阶段优化方法
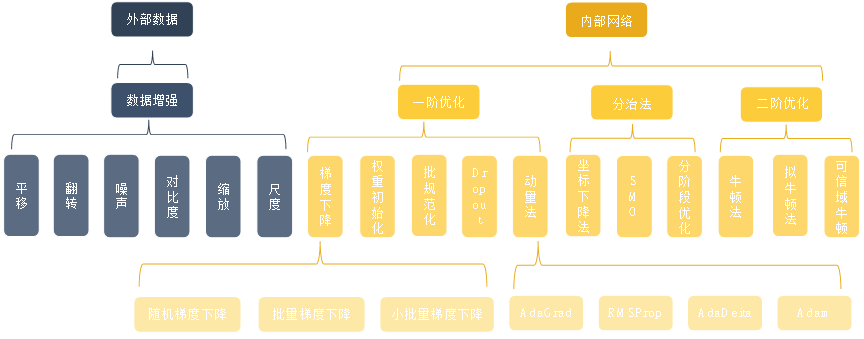
外部数据:数据增强
其中具体方式有:平移、 翻转、噪声、对比度、缩放、尺度变换
内部网络:
一阶优化:
- 梯度下降:随机梯度下降、批量梯度下降、小批量梯度下降
- 权重初始化
- 批规范化
- Dropout
- 动量法:AdaGrad RMSProp AdaDeita Adam
分治法:
- 坐标下降法
- SMO
- 分阶段优化
二阶优化:
牛顿法
拟牛顿法
可信域牛顿
推理阶段优化方法
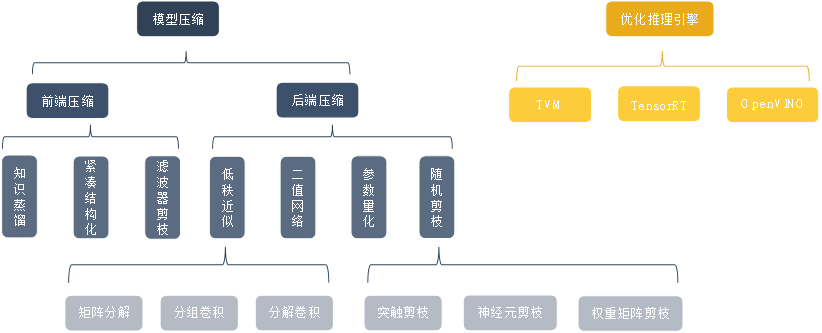
模型压缩:
- 前端压缩:
- 知识蒸馏
- 模型紧凑结构化
- 滤波器剪枝
- 后端压缩:
- 低秩近似:矩阵分解、分组卷积、卷积分解
- 网络二值化
- 参数量化
- 随机剪枝:突触剪枝、神经元剪枝、权重矩阵剪枝
- 前端压缩:
优化推理引擎
TVM
TensorRT
OpenVINO
TensorRT加速原理
TensorRT优化方式
- 权重与激活精度校准:通过将模型量化为 INT8 来更大限度地提高吞吐量,同时保持高准确度
- 层与张量融合:通过融合内核中的节点,优化 GPU 显存和带宽的使用
- 内核自动调整:基于目标 GPU 平台选择最佳数据层和算法
- 动态张量显存:更大限度减少显存占用,并高效地为张量重复利用内存
- 多流执行:用于并行处理多个输入流的可扩展设计
优化方式的可行性分析
- 样本数据中存在角度、目标位置、目标姿态以及数据噪声,通过训练,我们获得具有强鲁棒性的模型,该模型对噪声有一定的容忍度。所以当进行推理时,我们便可以将FP32数据转低精度执行,引起的误差视为引入噪声,噪声引进的变动同样会使各个层的激活值输出发生变动,然而却对结果影响不大,所以以低精度推理是可行的;
- 推理中的时间消耗主要集中在:
- 每次启动CUDA核心需要大量时间
- 每一层输入/输出张量的读写耗时
所以按照一般推理工作流,数据流经每一层都需要输入输出以及调用,势必造成时间线越拉越长,因此层与张量融合就是通过聚合具有足够相似参数和相同源张量的operations,减少调用CUDA次数,将零碎数据整理到一起传输,减少向CPU传输次数,最终实现减少横向时间
- 在每个tensor的使用期间,TensorRT会为其指定显存,避免显存重复申请,减少内存占用和提高重复使用效率
- TensorRT里边调用了一些方法,以一个最合理的方式去调用、操作这些数据
- CUDA多流执行把数据在传输过程中进行计算,隐藏了传输部分
TensorRT & TF-TRT
TensorRT是由NVIDIA开发,而TF-TRT是由NVIDIA和Google TensorFlow团队共同开发
TensorRT的当前版本支持3种“解析器”:Caffe,UFF和ONNX。根据TensorRT 7.0.0发行说明中的“弃用Caffe解析器和UFF解析器”,不建议使用Caffe和UFF解析器,首选ONNX解析器
为了优化TensorFlow模型,您可以选择将pb转换为UFF或ONNX,然后转换为TensorRT引擎。如果模型中的某些层不被TensorRT支持(请查看此表),则可以:
- 用插件替换这些层;
- 在构建TensorRT引擎时不要包括这些层,而是获取TensorRT引擎输出并进行处理以后再完成这些层的功能
TF-TRT的优缺点:
优点:
- API易于使用;
- 无需担心插件。
缺点:
- 需要将整个TensorFlow库存储在平台中(这对部署环境不利)
- 需要在运行时将TensorFlow加载到内存中
- 通常比纯TensorRT引擎运行慢
UFF TensorRT引擎的运行速度通常比TF-TRT优化图快得多,原因可能如下:
在整个图上进行优化,而不仅仅是在图的单个节点或部分上。TF-TRT是针对部分优化,而TensorRT是对整个计算图做优化;
基于计算图不同的优化方式,所以在后续选择版精度FP16甚至INT8时,在TF-TRT情况下也仅在图形的某些优化部分上进行FP16/INT8计算
TensorRT在对CUDA内核的选取上有自己设计的优化机制,可以根据数据size\shape自动选取适合的CUDA内核,所以相较TF-TRT也是节省了时间