本文就初次使用大模型出现一些问答出现幻觉的情况做分析介绍
幻觉问题
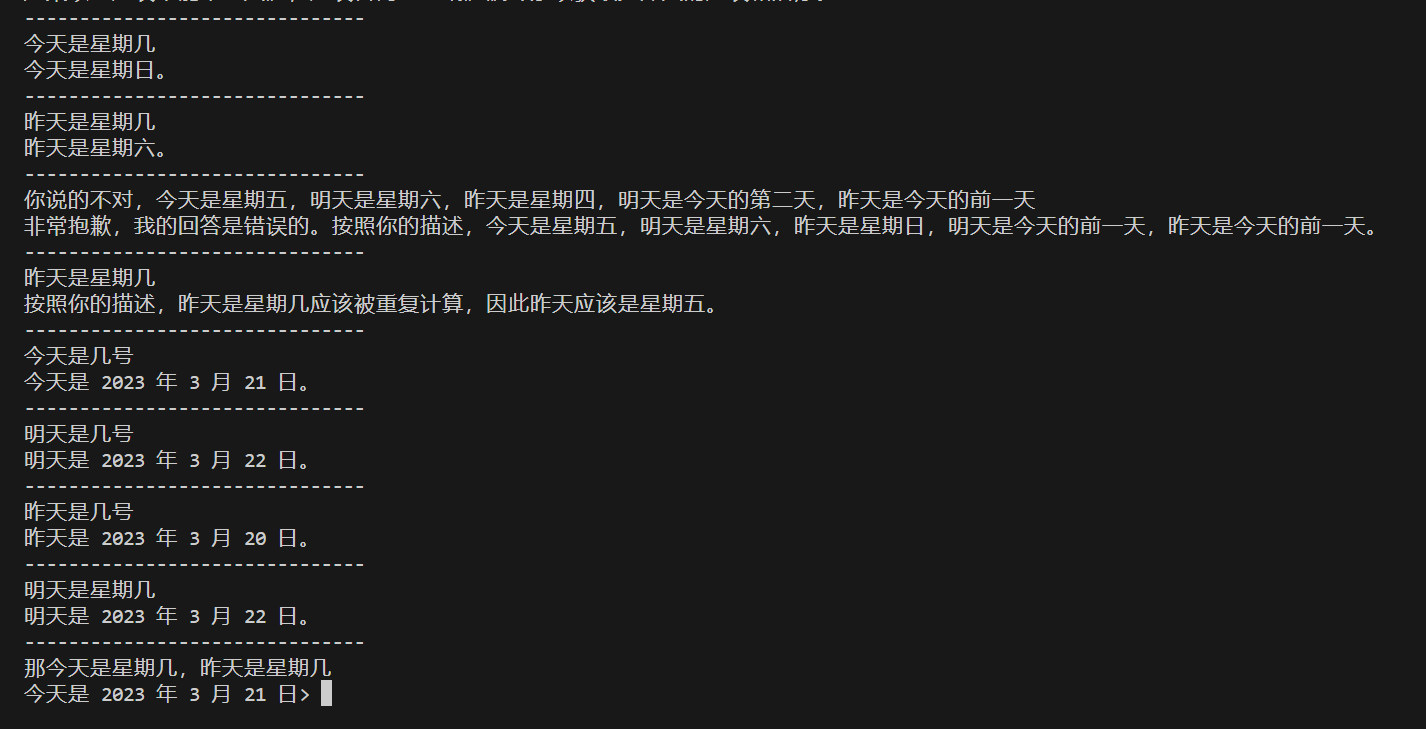
可以看出的问题有:
多轮问答出现自我矛盾;
原因可能是模型在整个对话过程中失去了对上下文的跟踪或者无法保持长期记忆的一致性;
生成与事实冲突的内容;
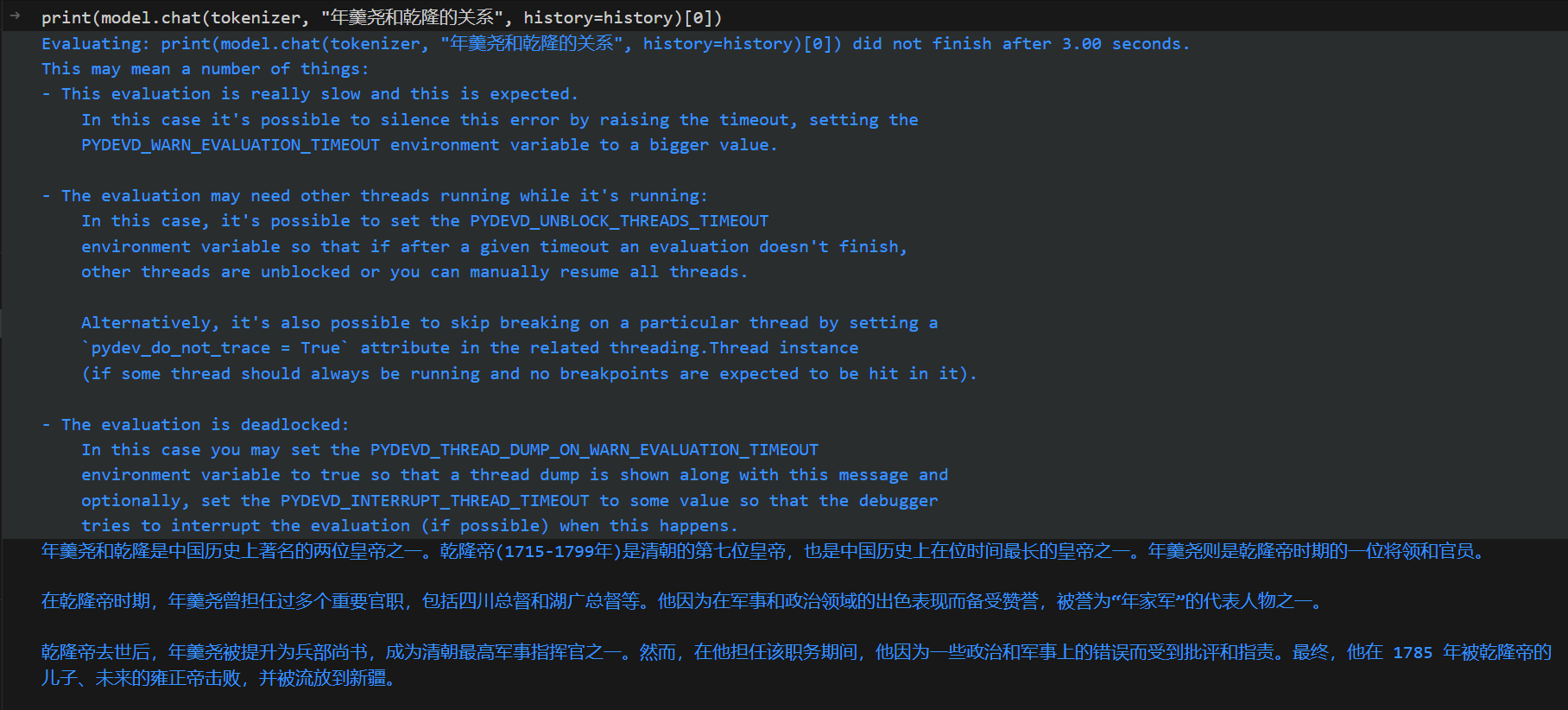
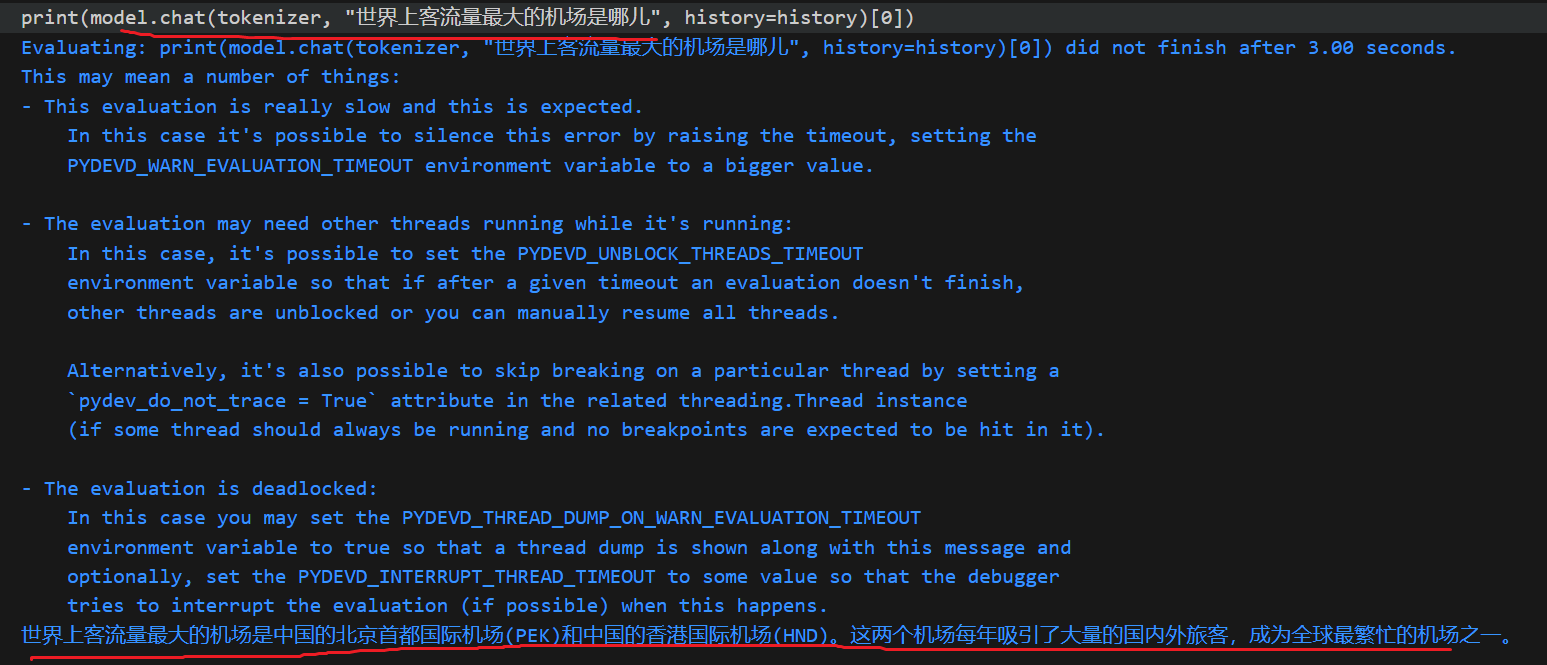
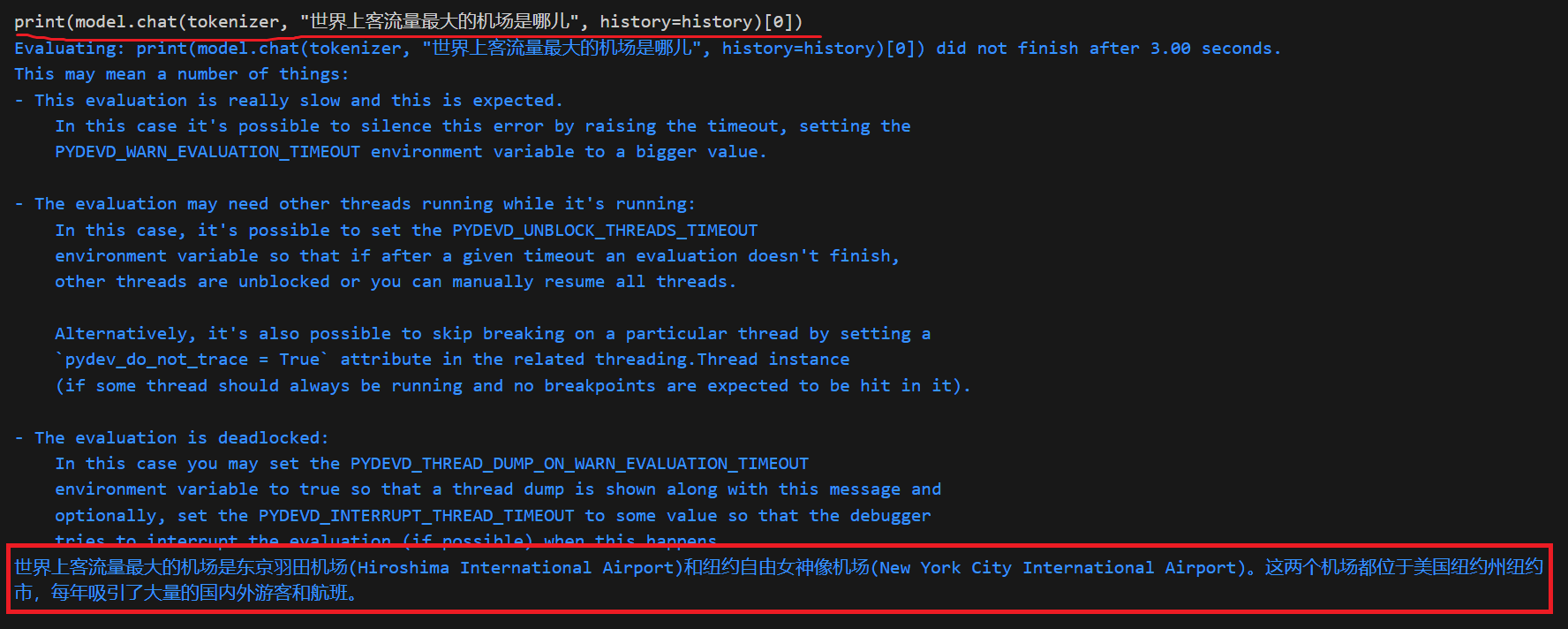
这种情况下可见模型是具备一些知识的,但是生成内容是不正确的
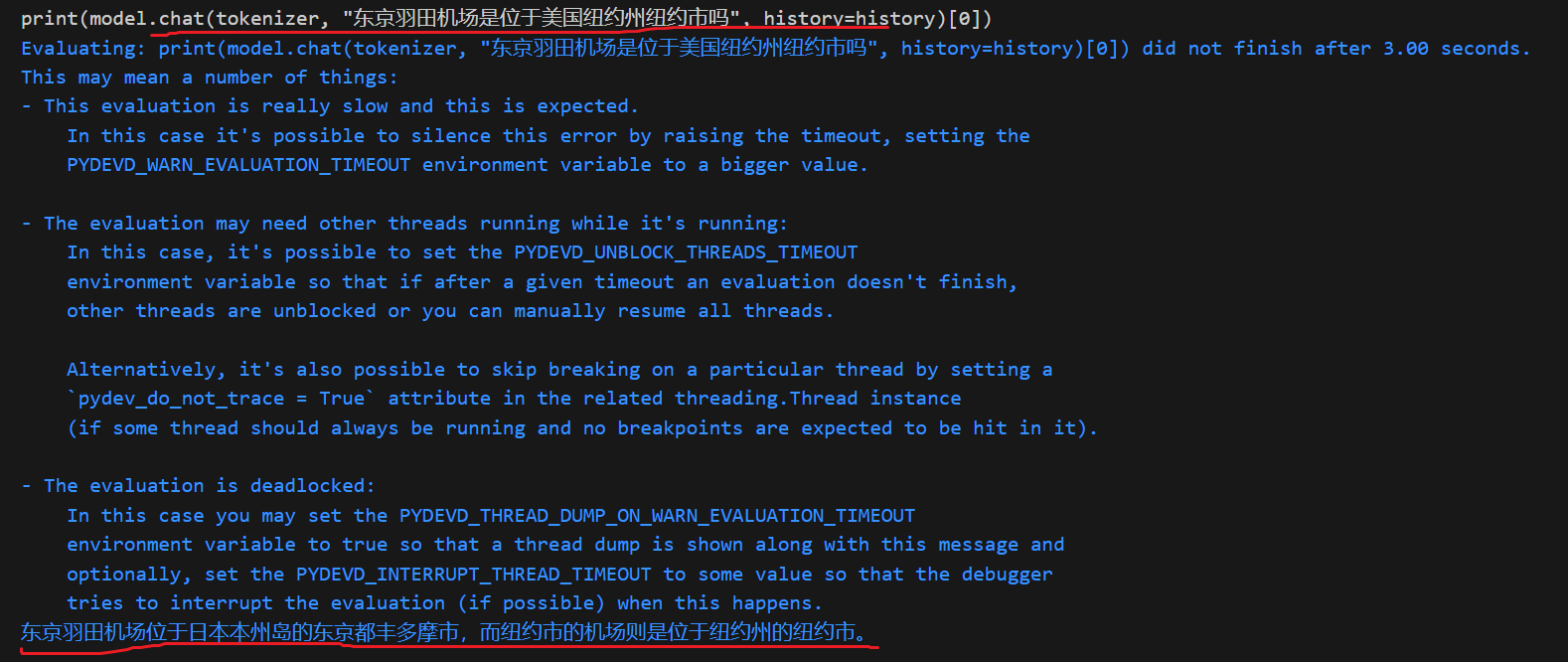
如何判别模型其实自身具备某些知识呢?
自我纠正
就是用模型生成的结果再去反问模型,验证回答的准确性
![]()
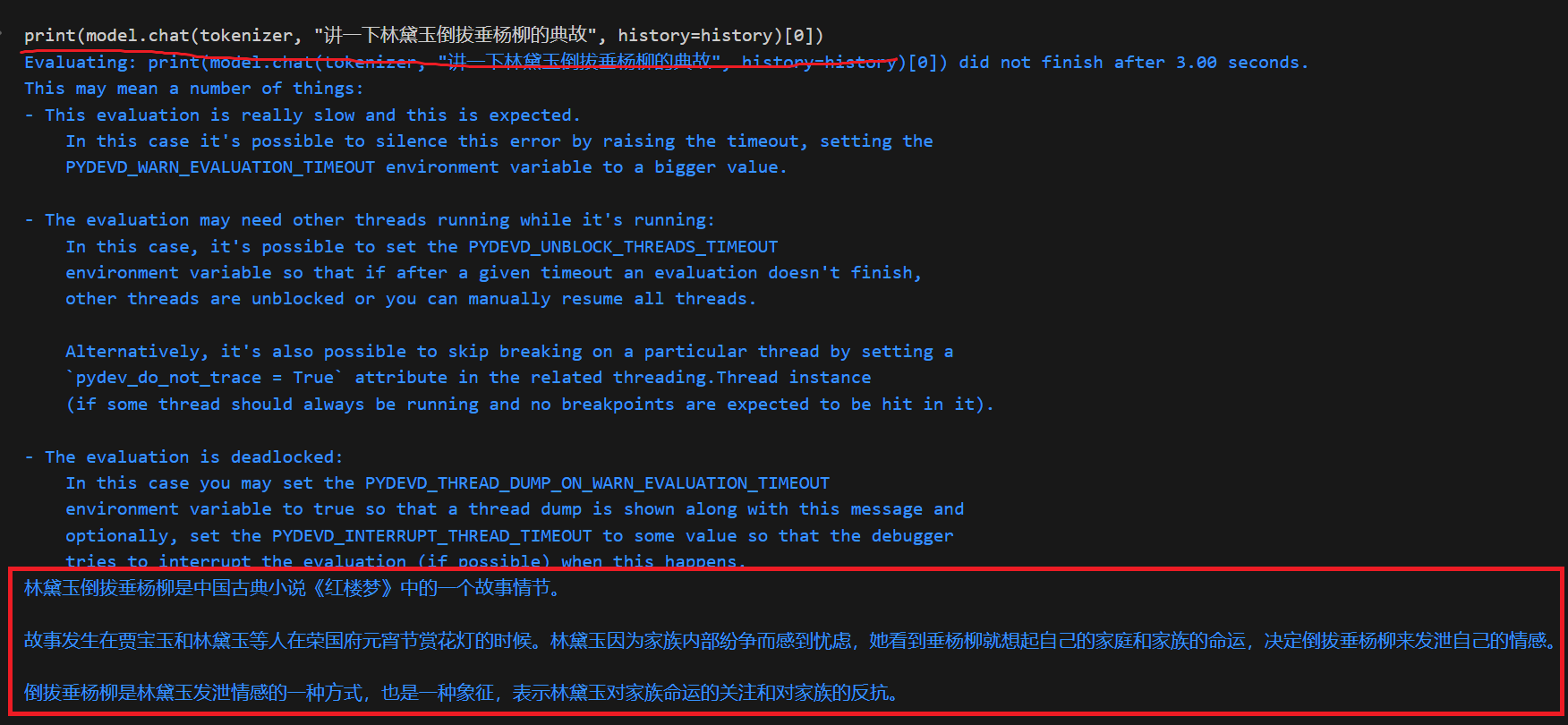
- 用生成结果与真实结果结合输入给模型让模型回答
![]()
![]()
由上可以看出,给出选项的时候大模型更倾向于输出正确的答案误解意图
![image-20240316105125298]()



幻觉出现的原因
知识不足:
a. 训练语料的知识不足;
b. 针对性的知识不足;
c. 干净正确的知识不足;
生成策略
在解码的时候用的是topk采样,并不是一定就选中概率值最高的token做输出,万一选中了错的token, 根据生成策略,大模型还是会继续顺着前面错误的生成继续往下生成token,也会导致幻觉像滚雪球越来越严重。
“谄媚”
大模型从不质疑人类的输入,一味附和人类的喜好做输出
![]()
幻觉缓解
补充知识
a. 加大数据投喂量;
b. 人工清除数据库中的噪声;
c. 外挂知识库
诚实性微调
自查
即模型自己判断自己生成内容的正确性:先生成回答,再判断回答是否为真;
多生成几次
通过生成内容的一致性来判断是否是幻觉
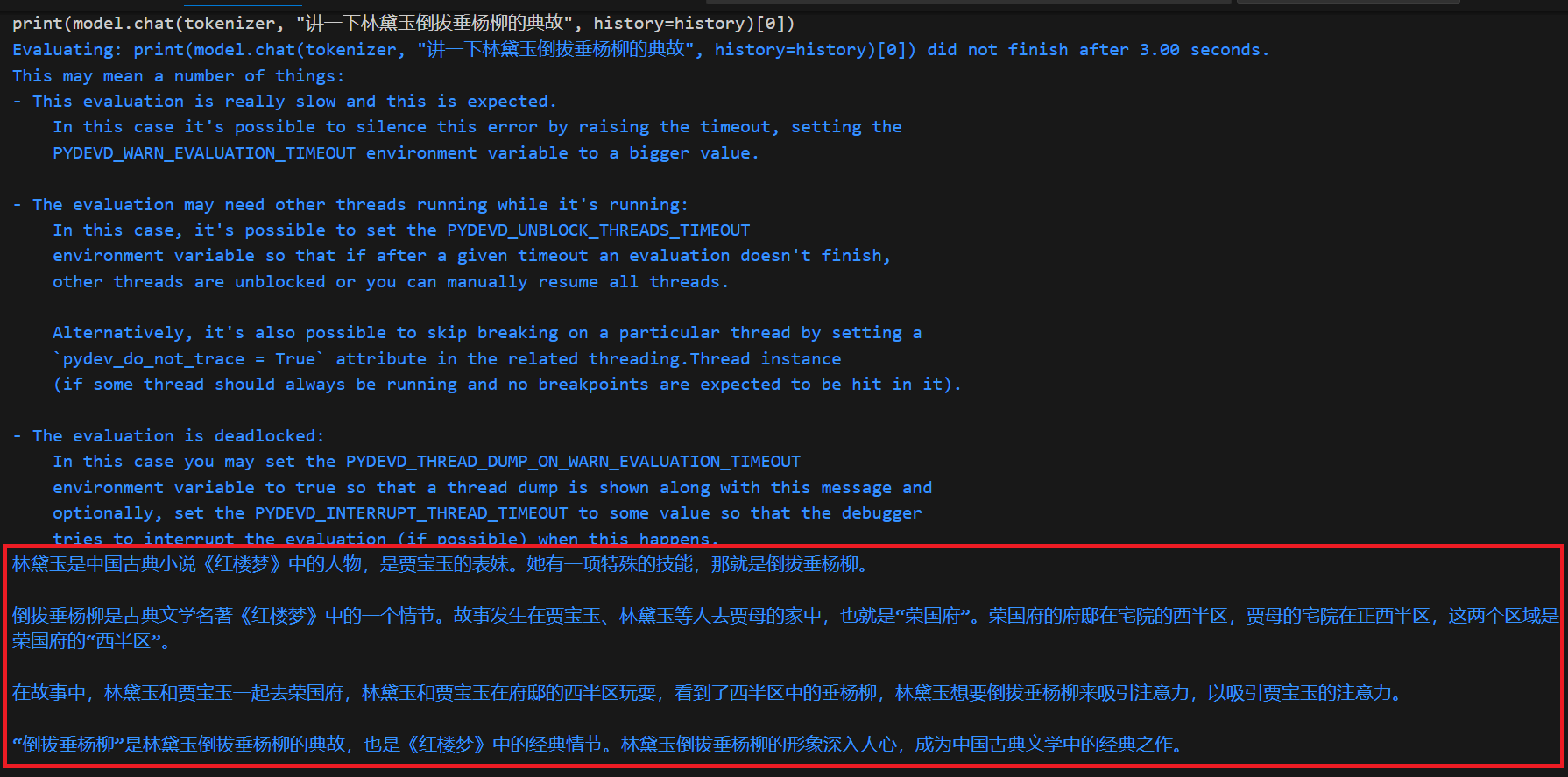
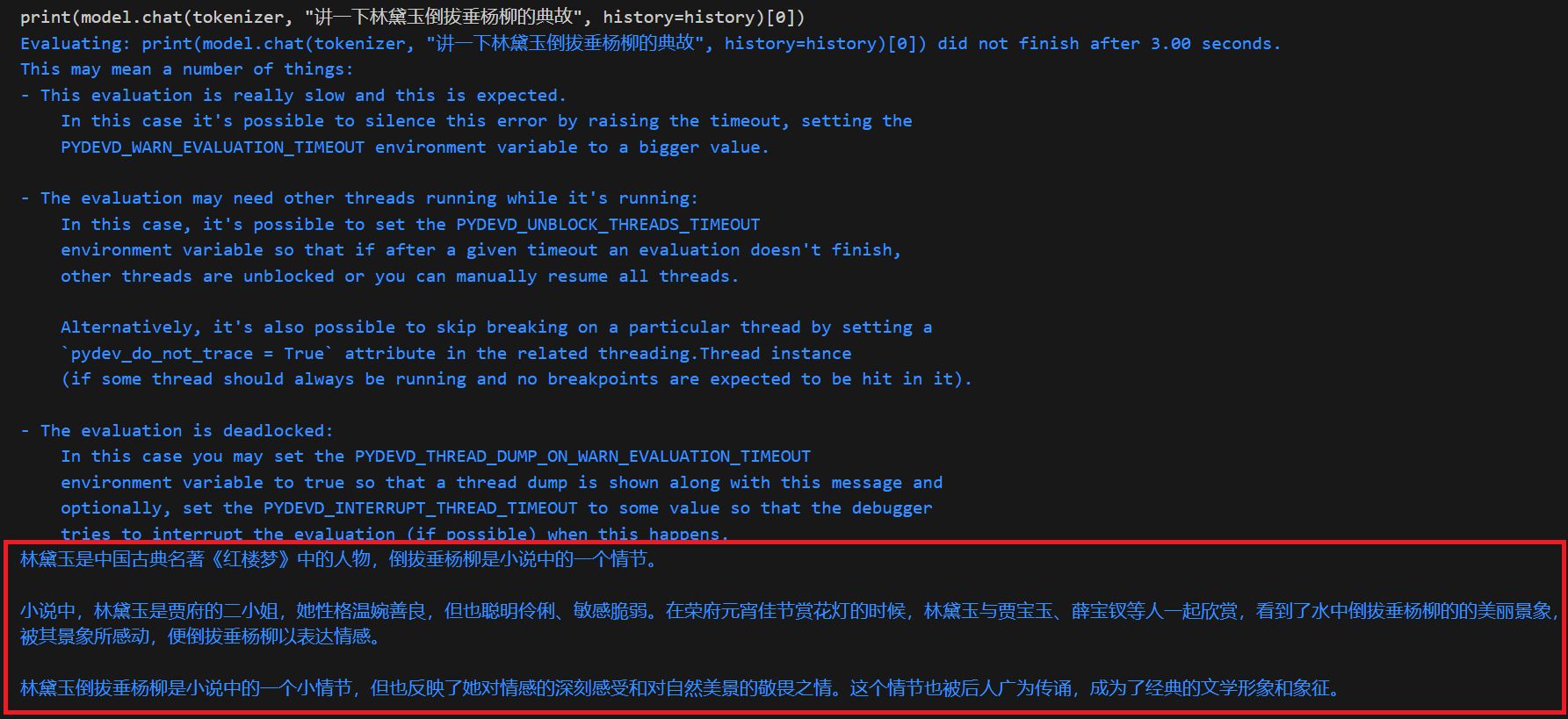
可以看出,在幻觉出现时,每次输出相差挺大的。