本文就实践中遇到的幻觉现象以及web端部署大模型做实验介绍
大模型表现 幻觉的回答 表现是文本搜索结果中并没有相关的文段内容,所以大模型自由发挥胡说八道,不知道真实答案的人很容易被误导。原因可能是:
资料路中相关语料内容本来就少;
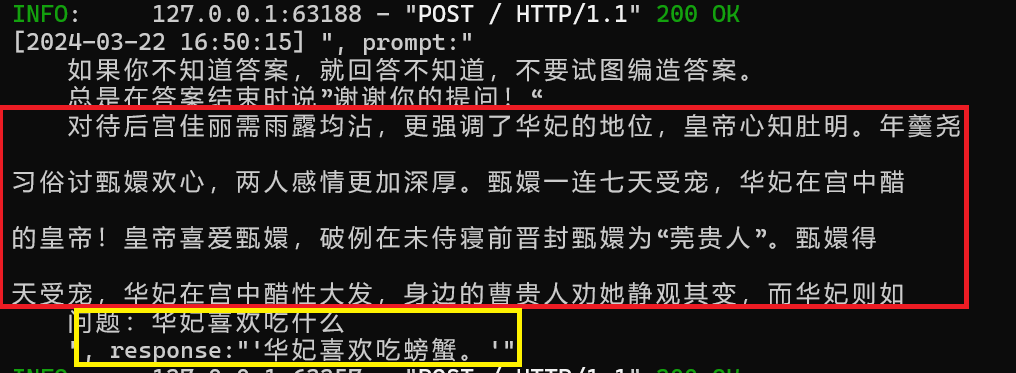
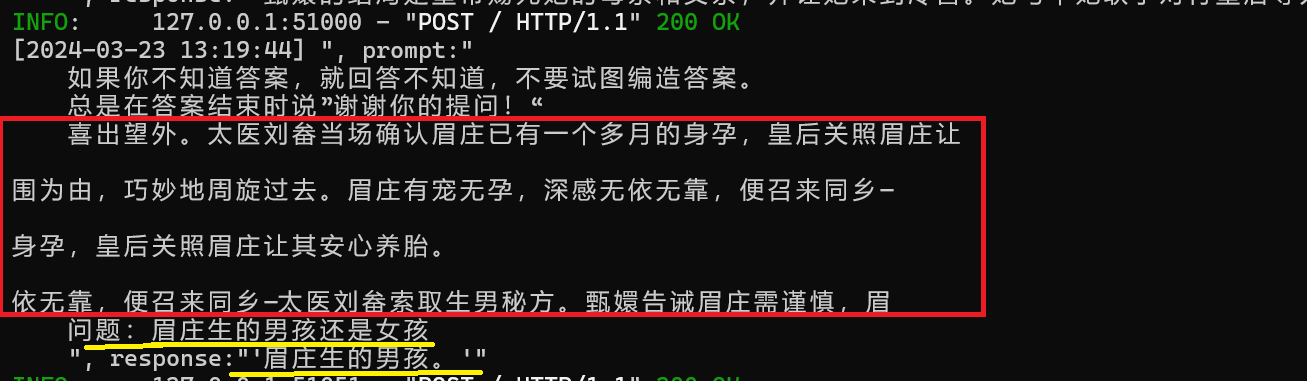
原本语料库根本没有提及到华妃喜欢食物的相关内容
对象出现的频率很小的时候很容易被误认为是其他高频出现的对象;
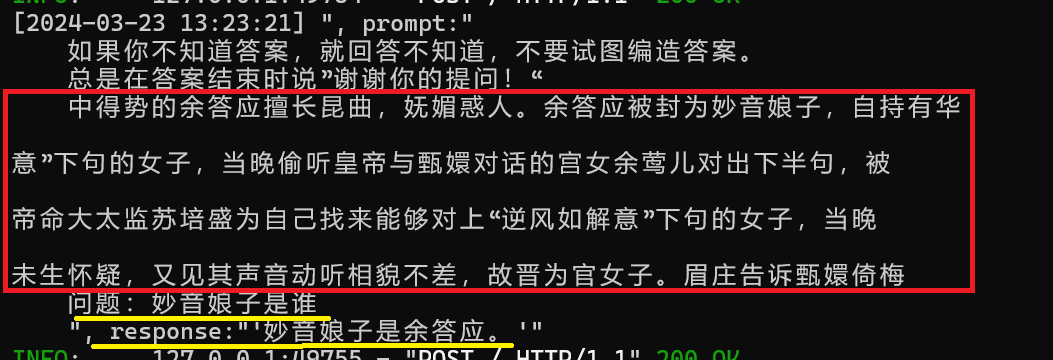
把康禄海当成年羹尧了,原始文本中年羹尧出现31次,康禄海出现2次
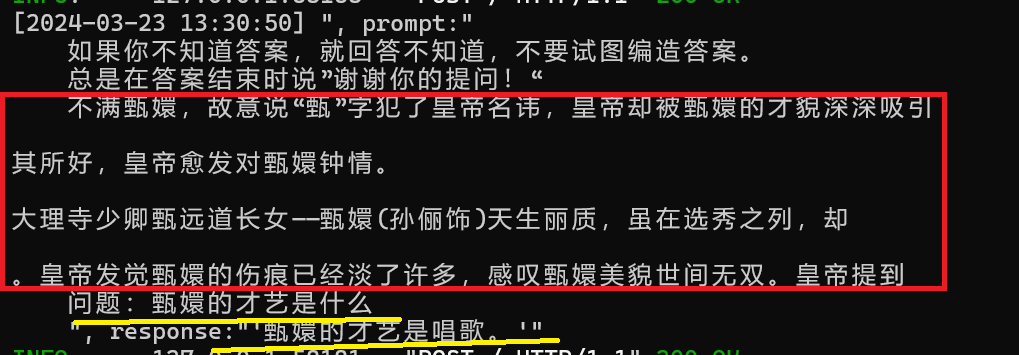
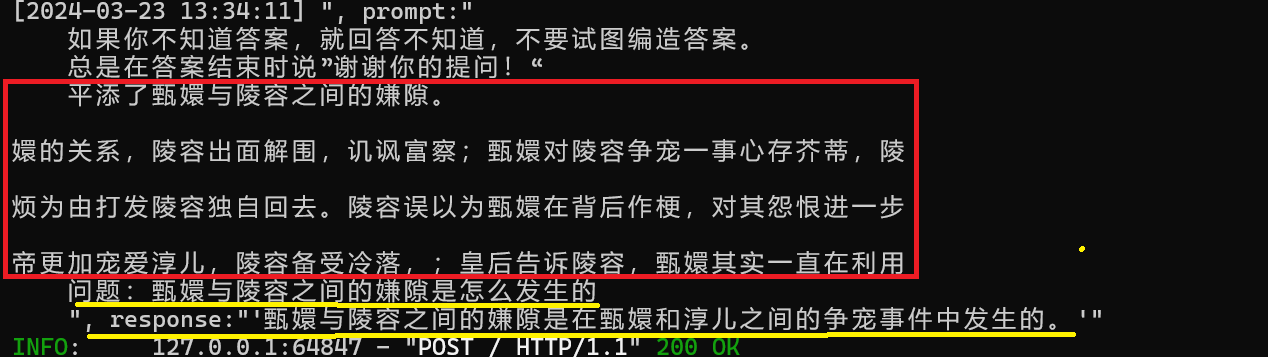
大模型是生成内容,前面文本出现的时候,大模型后面生成内容很容易生成常见的、极易出现的语句对,比如说天气是晴朗的,才艺是唱歌之类的。
大模型自由发挥
大模型有时候会对输入问题出现误解,所以这时候的回答也就是错的
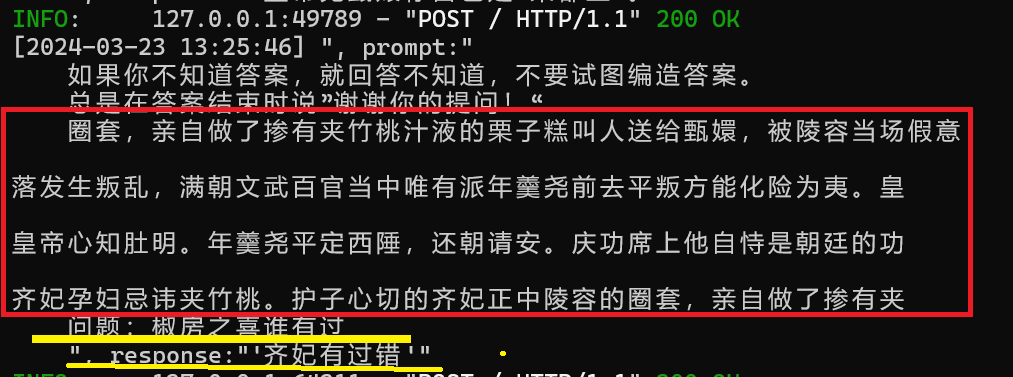
这里我提问的其实谁拥有过椒房之宠,大模型理解成谁有过错
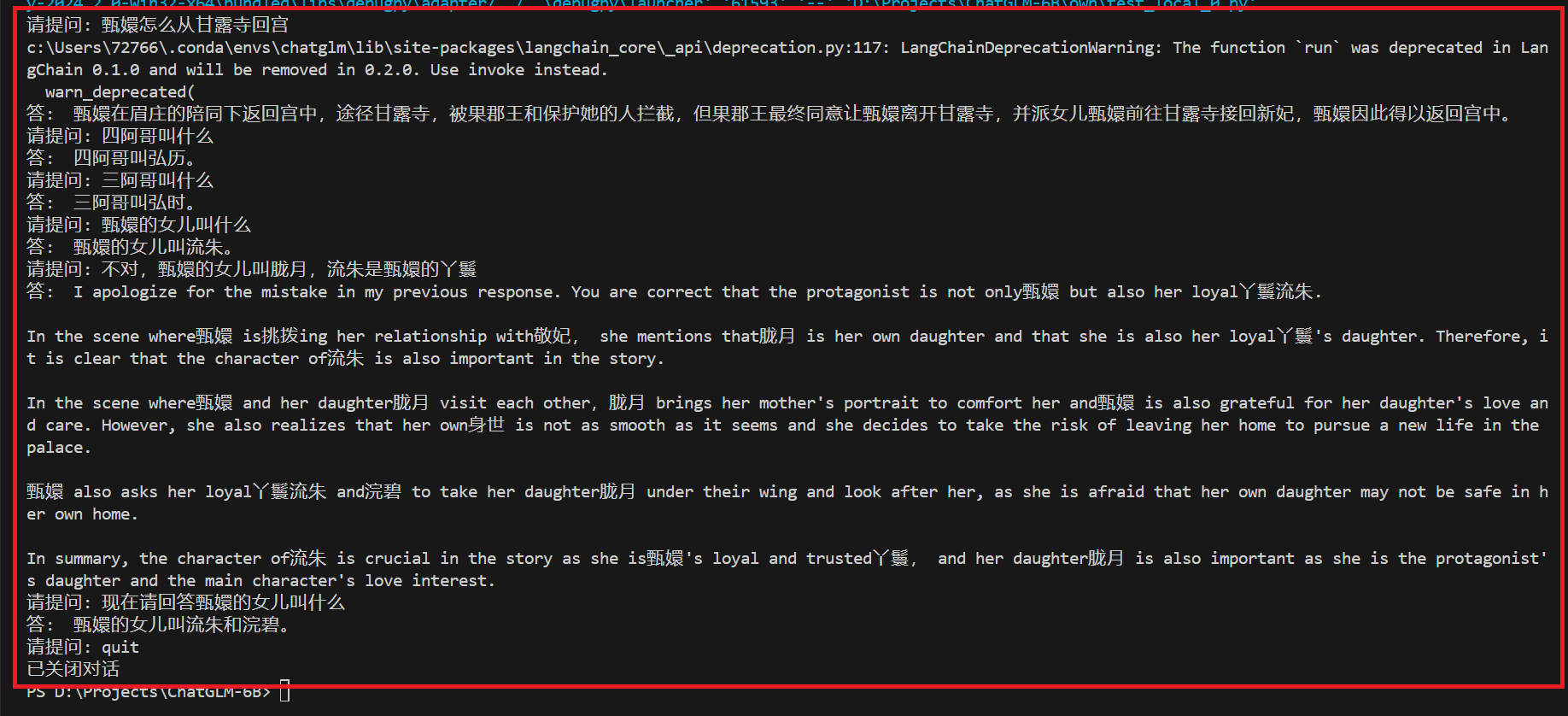
不错的回答
至此,本地部署最简单的方式已经完成,这里给出部署代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from langchain.vectorstores.chroma import Chromafrom langchain.document_loaders.text import TextLoaderfrom langchain.embeddings.huggingface import HuggingFaceEmbeddingsfrom langchain.text_splitter import RecursiveCharacterTextSplitterimport ospersist_directory = 'vector_zhenhuanzhuan_32' model_name = "shibing624/text2vec-base-chinese" model_kwargs = {'device' : 'cuda:0' } encode_kwargs = {'normalize_embeddings' : False } hf = HuggingFaceEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs ) db = None if os.path.exists(persist_directory): db = Chroma(embedding_function=hf, persist_directory=persist_directory) else : loader = TextLoader('甄嬛传剧情.txt' , encoding='utf-8' ) text_split = RecursiveCharacterTextSplitter( chunk_size = 32 , chunk_overlap = 10 , length_function = len , add_start_index = True ) split_docs = text_split.split_documents(loader.load()) db = Chroma.from_documents(documents=split_docs, embedding=hf, persist_directory=persist_directory) db.persist() ques = '华妃终身不孕的原因是什么' res_similarity_search = db.similarity_search(ques) print ('over' )
调用大模型开启对话
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from langchain.vectorstores.chroma import Chromafrom langchain.embeddings.huggingface import HuggingFaceEmbeddingsfrom langchain.llms.chatglm import ChatGLM from langchain.chains import RetrievalQApersist_directory = 'vector_zhenhuanzhuan_32' model_name = "shibing624/text2vec-base-chinese" model_kwargs = {'device' : 'cuda:0' } encode_kwargs = {'normalize_embeddings' : False } embeddings = HuggingFaceEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs ) db = Chroma(embedding_function=embeddings, persist_directory=persist_directory) llm = ChatGLM( endpoint_url='http://127.0.0.1:8000' , max_token=2000 , top_p=0.7 ) retriever = db.as_retriever() qa = RetrievalQA.from_chain_type( llm=llm, retriever = retriever, chain_type= "stuff" ) while True : question = input ("请提问: " ) if question == "quit" : print ("已关闭对话" ) break else : response = qa.run(question) print ("答: " , response)
本地部署的改进 中英文夹杂 解决办法:promt
1 2 3 4 5 6 7 8 9 while True : question = input ("请提问: " ) if question == "quit" : print ("已关闭对话" ) break else : question +="。无法回答就说不知道,用中文回答。" response = qa.run(question) print ("原始回答: " , response)
webUI端部署 首先安装依赖
网页端部署脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from langchain.vectorstores.chroma import Chromafrom langchain.embeddings.huggingface import HuggingFaceEmbeddingsfrom langchain.llms.chatglm import ChatGLM from langchain.chains import RetrievalQAimport tracebackpersist_directory = 'vector_zhenhuanzhuan_32' model_name = "shibing624/text2vec-base-chinese" model_kwargs = {'device' : 'cuda:0' } encode_kwargs = {'normalize_embeddings' : False } embeddings = HuggingFaceEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs ) db = Chroma(embedding_function=embeddings, persist_directory=persist_directory) llm = ChatGLM( endpoint_url='http://127.0.0.1:8000' , max_token=2000 , top_p=0.7 ) retriever = db.as_retriever() qa = RetrievalQA.from_chain_type( llm=llm, retriever = retriever, chain_type= "stuff" ) def chat (question, history ): response = qa.run(question) return response try : import gradio as gr demo = gr.ChatInterface(chat) demo.launch(inbrowser=True , share= True ) except : print (traceback.format_exc())
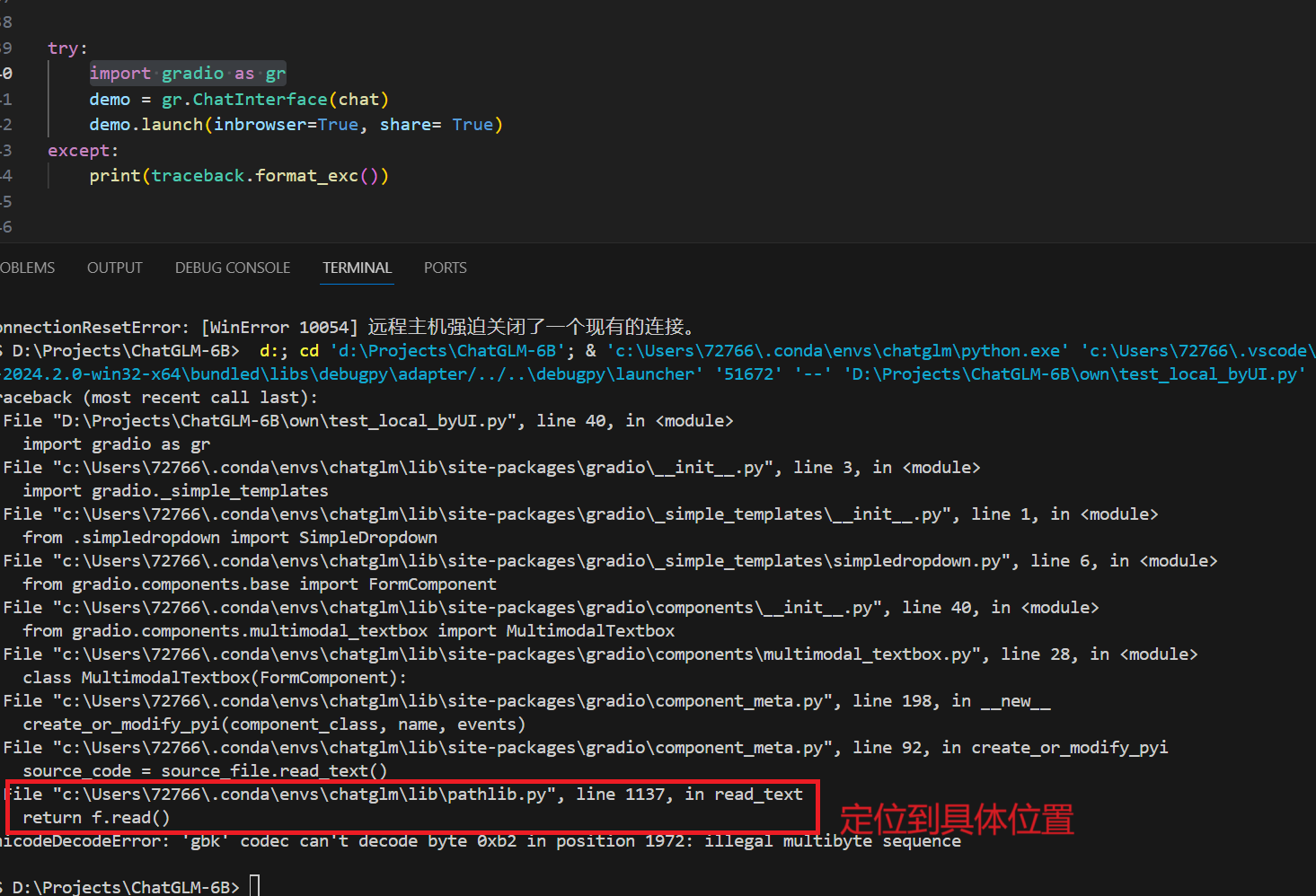
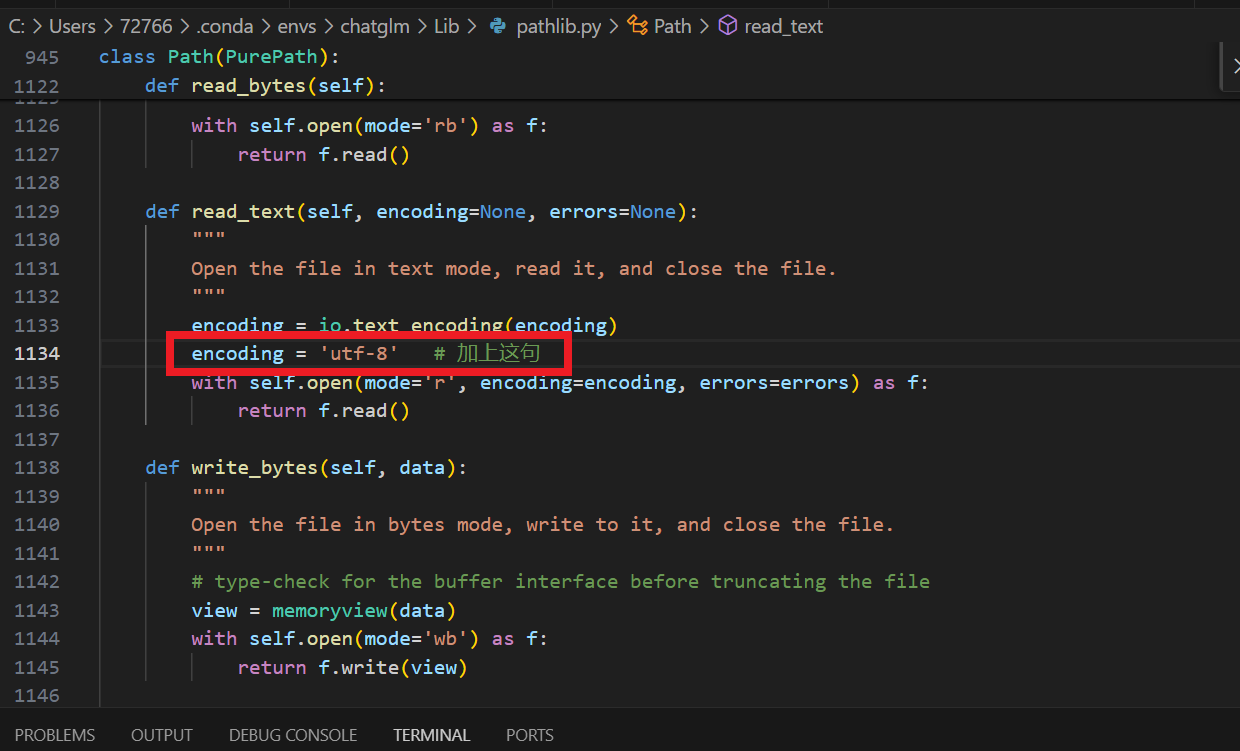
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xb2 in position 1972: illegal multibyte sequence 开始问题出现在import gradio as gr,为了定位具体位置,加上traceback,最后找到是在read部分出现读入错误。
所以在原位置加上指定utf-8编码
再次运行问题解决
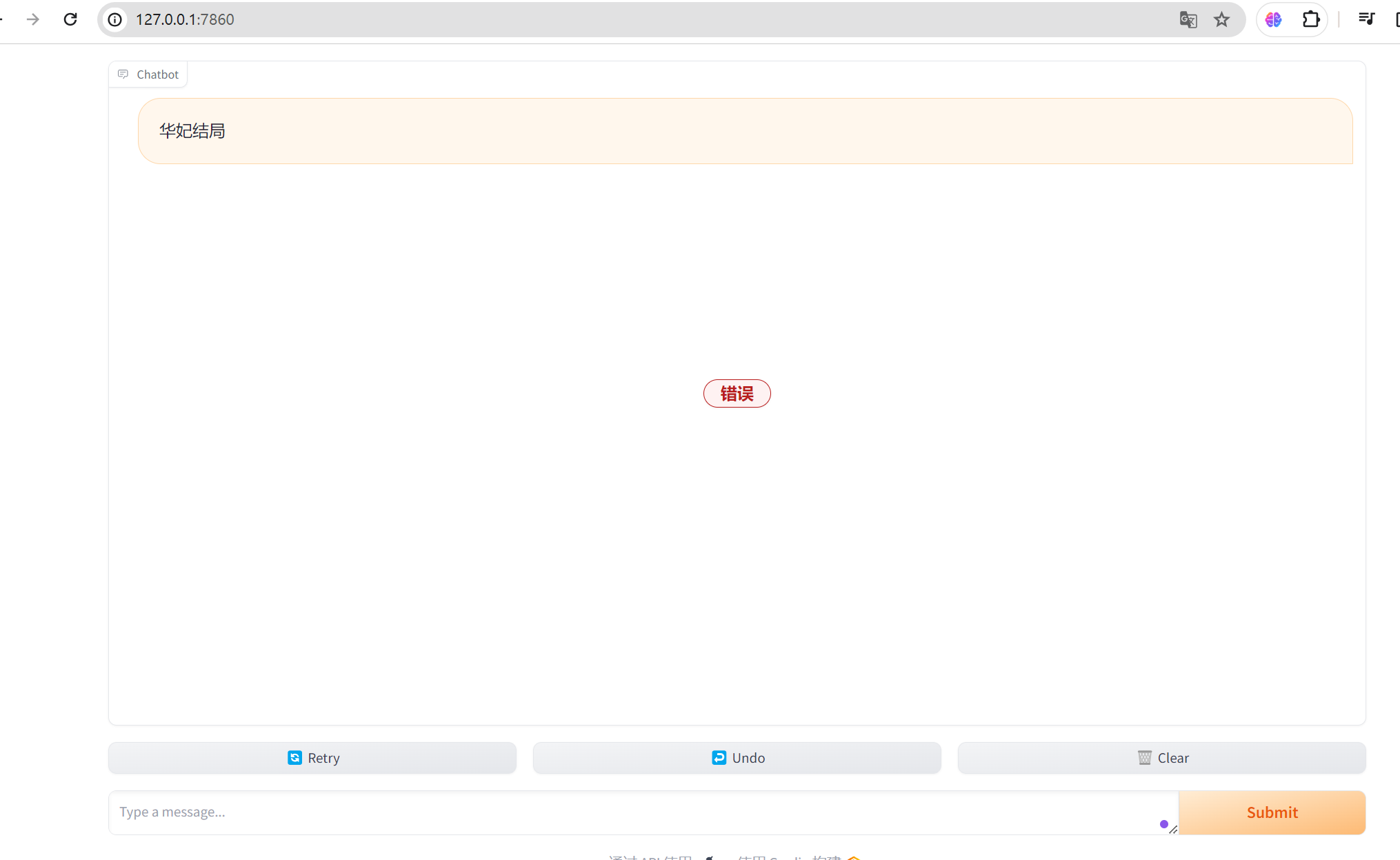
TypeError: chat() takes 1 positional argument but 2 were given 网页打开后输入问题报错
这里一定注意
1 2 3 def chat (question, history ): response = qa.run(question) return response
加上history问题解决。
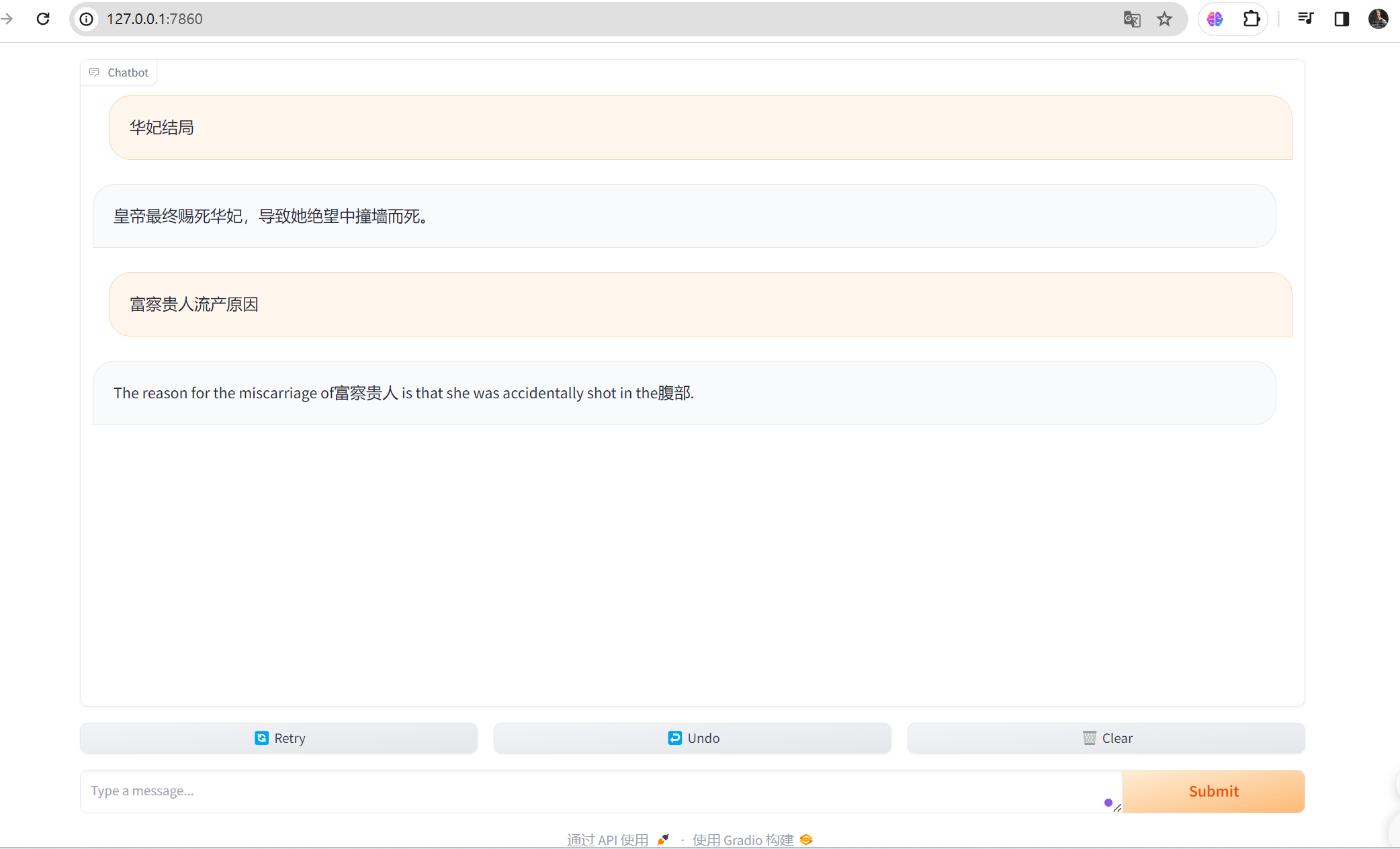
最后正常运行的结果如下:
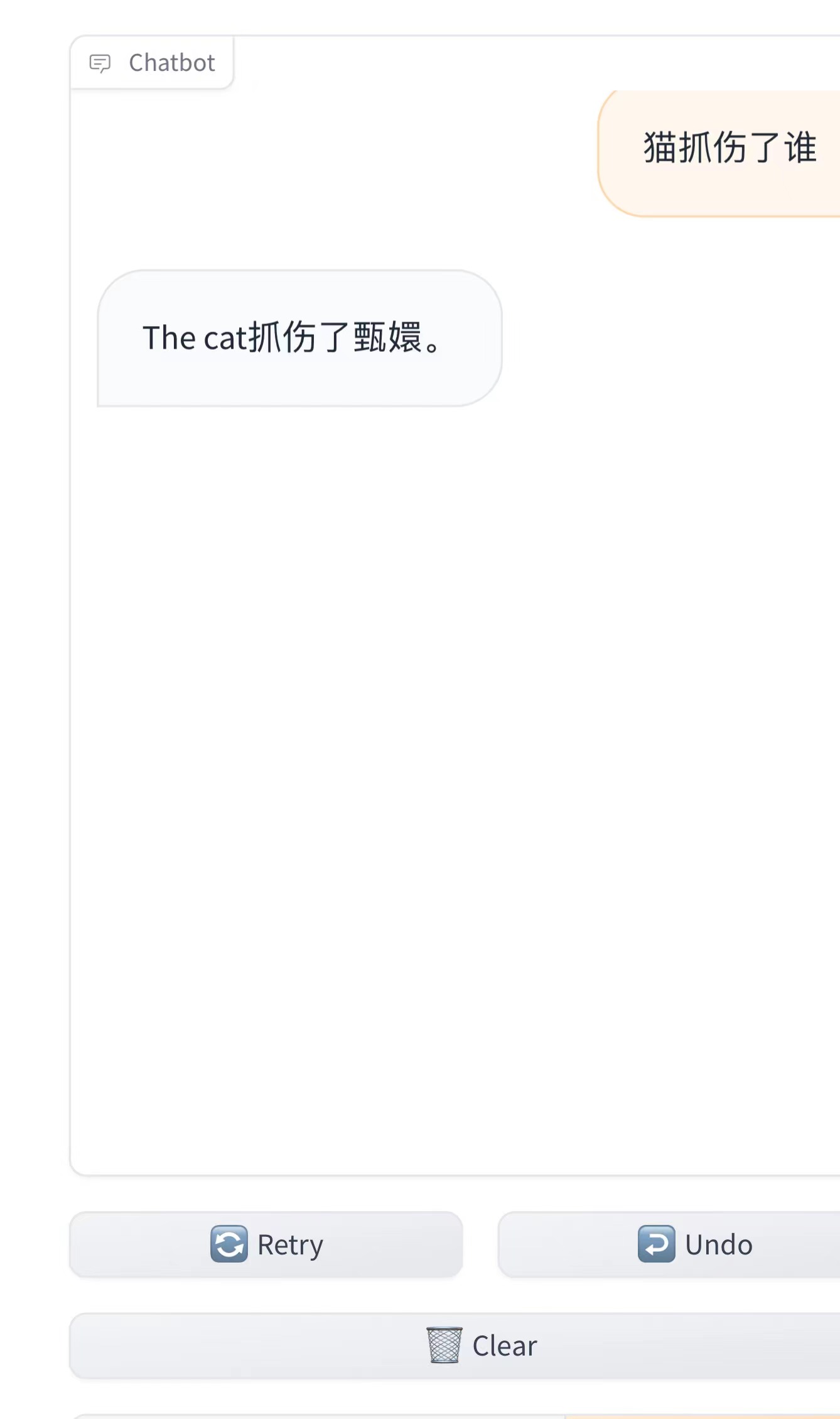
加了共享链接在手机上运行也是正常的