本文就如何使用爬虫工具实现文本抓取进行验证介绍
数据收集
开始我下载的是小说,但是发现小说和我所知道的电视剧改动比较大,而且小说的语法用词不太白话文,后面又想着字幕是不是好一点,但是忽略了字幕会跳过最重要的环节:人物关系,也就是丢给大模型,它并不明白这话都是谁说的,无法联系起来。所以最终决定从分集剧情作为数据,更简单干练。
因为我要从网站上把每集的分集剧情内容爬下来,所以不得不提爬虫工具。
网页不可复制代码块内容提取
1
2
3
4
5
6
7
8
9
10
11
|
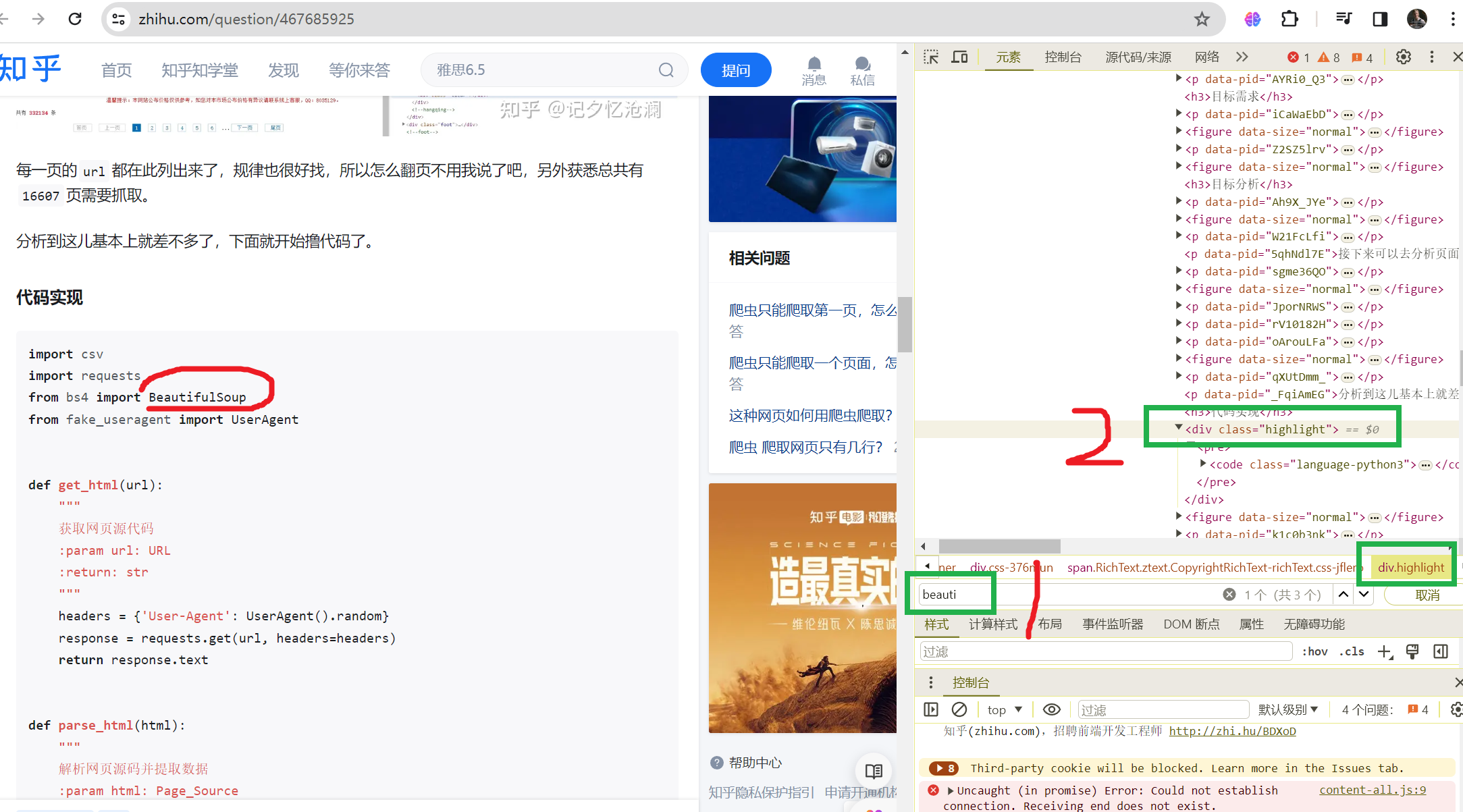
import requests
from bs4 import BeautifulSoup
url = "https://www.zhihu.com/question/467685925"
response = requests.get(url)
html_content = response.content
soup = BeautifulSoup(html_content, "html.parser")
class_element = soup.find('div', class_='highlight')
class_text = class_element.text
print(class_text)
|
![]()
可以看下效果
![]()
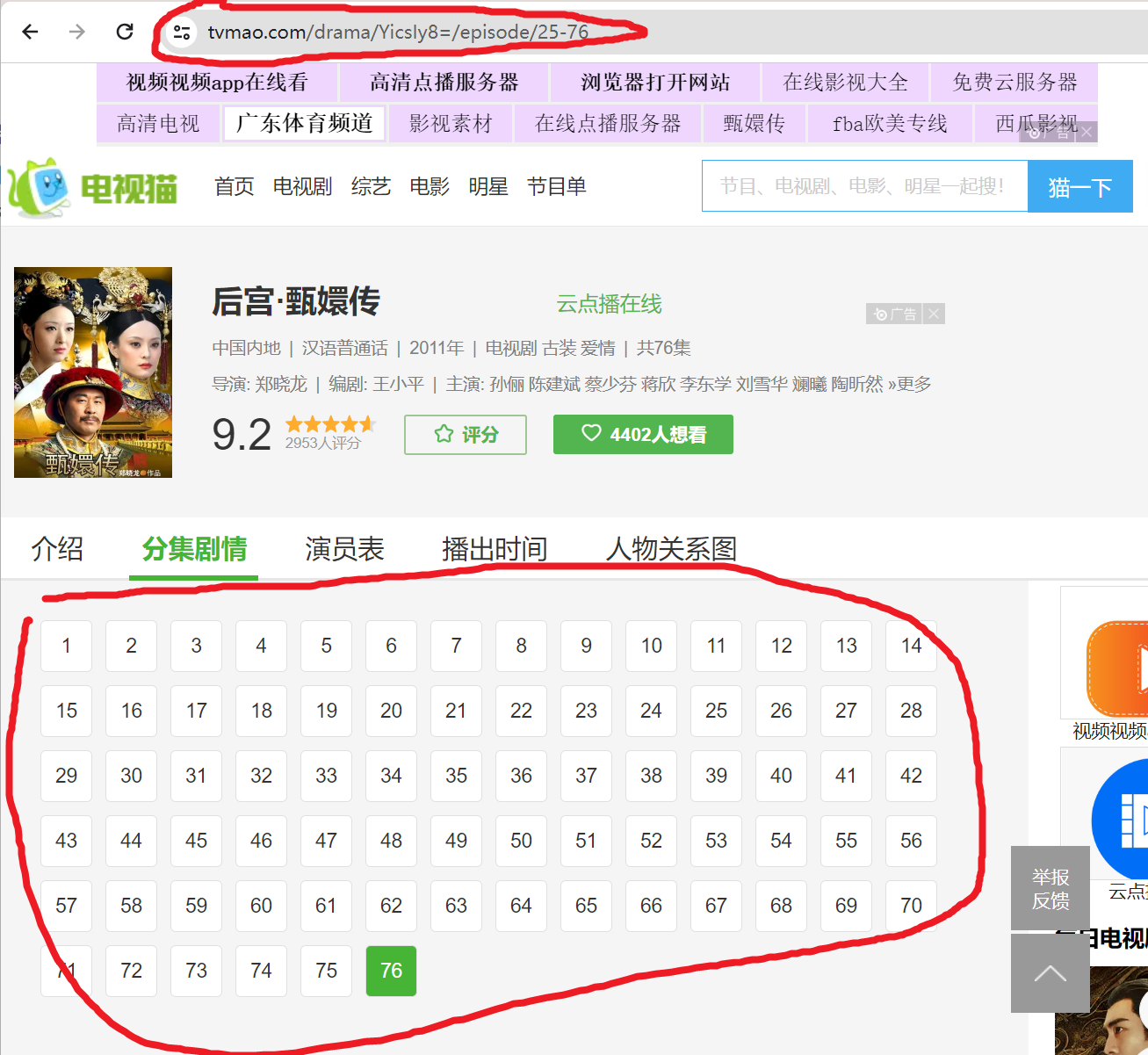
带有下一页格式网页内容提取
![]()
观察网页格式可以得到网页命名格式
1
2
3
4
5
6
7
8
9
10
11
| '''
https://www.tvmao.com/drama/YicsIy8=/episode
https://www.tvmao.com/drama/YicsIy8=/episode/0-2
https://www.tvmao.com/drama/YicsIy8=/episode/0-3
https://www.tvmao.com/drama/YicsIy8=/episode/1-4
https://www.tvmao.com/drama/YicsIy8=/episode/1-5
https://www.tvmao.com/drama/YicsIy8=/episode/1-6
https://www.tvmao.com/drama/YicsIy8=/episode/20-63
https://www.tvmao.com/drama/YicsIy8=/episode/21-64
https://www.tvmao.com/drama/YicsIy8=/episode/25-76
'''
|
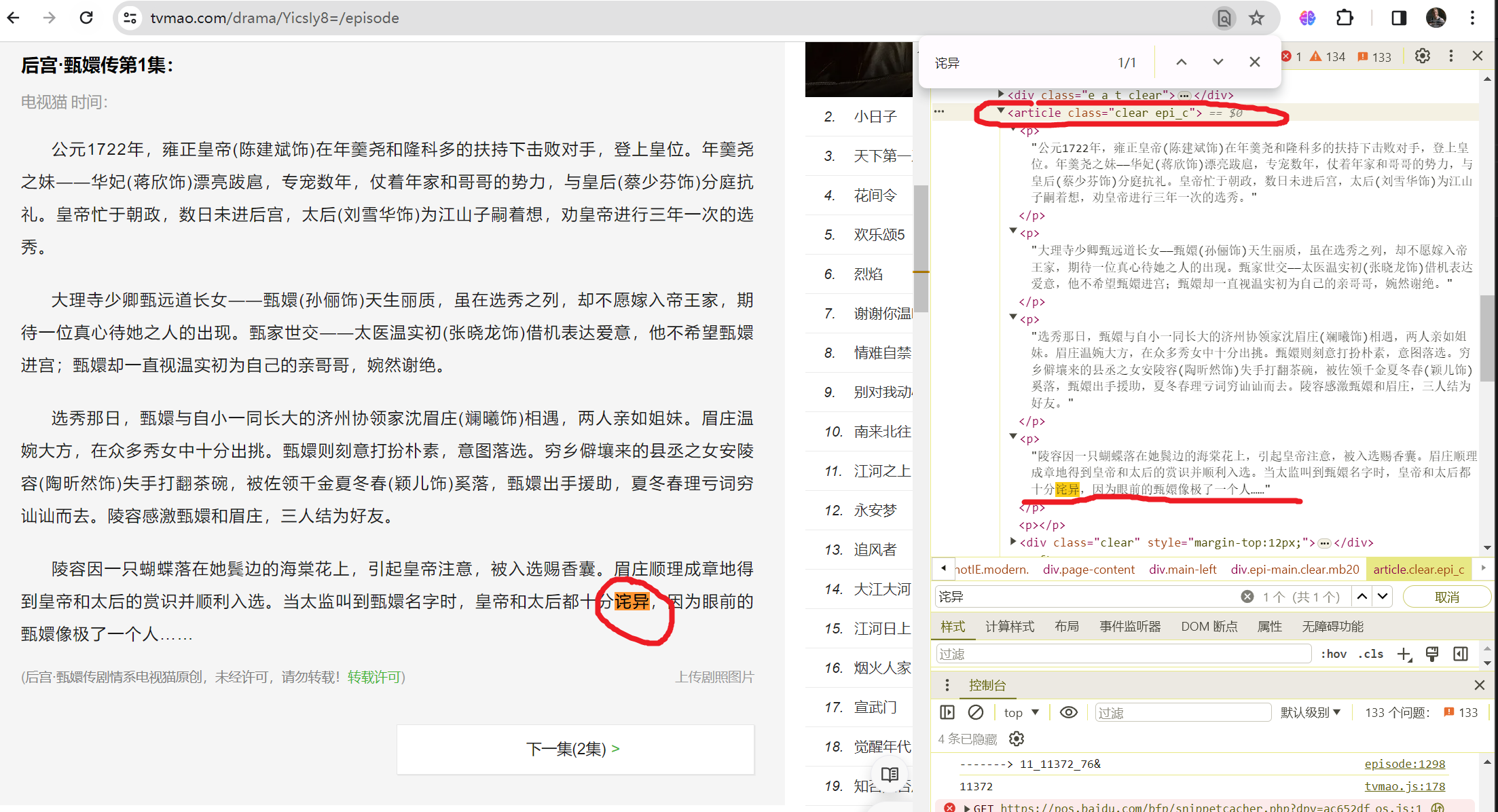
所以中心思想是遍历所有网页再根据关键信息提取对应的块内容
![]()
这里一定注意:1.查找时尽量找文本最后的字符为查找对象,才能找对,文档前面的字符可能会在网页源码中多次出现,不注意的话很容易找错地方。2. 文本提取出来看看有没有不相关的内容尽早清洗剔除掉,保证数据干净
所以整体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
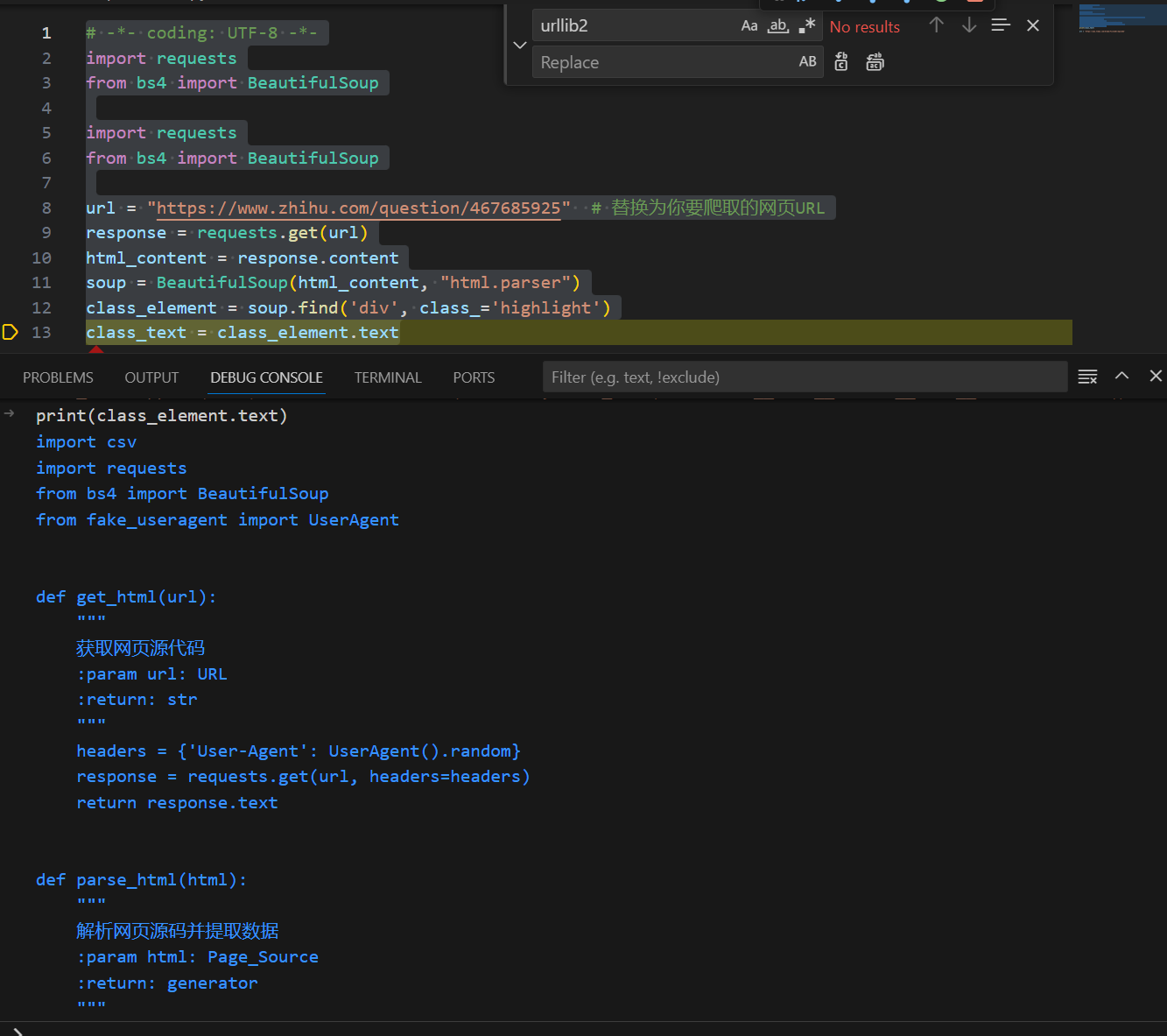
| import csv
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
def get_html(url):
"""
获取网页源代码
:param url: URL
:return: str
"""
headers = {'User-Agent': UserAgent().random}
response = requests.get(url, headers=headers)
return response.text
def parse_html(html):
"""
解析网页源码并提取数据
:param html: Page_Source
:return: generator
"""
soup = BeautifulSoup(html, 'html.parser')
class_element = soup.find('article', class_='clear epi_c')
description = class_element.text
description = description.replace('(后宫·甄嬛传剧情系电视猫原创,未经许可,请勿转载!转载许可)', "").replace("上传剧照图片", '').strip()+ '\n'
print(description)
return description
def write2csv(filename, rows):
"""
保存数据到csv文件
:param filename:
:param rows:
:return:
"""
with open(filename, 'a+', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerows(rows)
def write2txt(filename, contents):
fh = open(filename, 'a+', encoding='utf-8')
fh.write(contents)
fh.close()
def main():
"""
入口函数
:return:
"""
filename = './甄嬛传剧情.txt'
'''
https://www.tvmao.com/drama/YicsIy8=/episode
https://www.tvmao.com/drama/YicsIy8=/episode/0-2
https://www.tvmao.com/drama/YicsIy8=/episode/0-3
https://www.tvmao.com/drama/YicsIy8=/episode/1-4
https://www.tvmao.com/drama/YicsIy8=/episode/1-5
https://www.tvmao.com/drama/YicsIy8=/episode/1-6
https://www.tvmao.com/drama/YicsIy8=/episode/20-63
https://www.tvmao.com/drama/YicsIy8=/episode/21-64
https://www.tvmao.com/drama/YicsIy8=/episode/25-76
'''
for index in range(1, 77):
shang = index//3
rest = index%3
if rest==0:
pageNo = shang -1
else:
pageNo = shang
if index ==1:
url = 'https://www.tvmao.com/drama/YicsIy8=/episode'
else:
url = 'https://www.tvmao.com/drama/YicsIy8=/episode/{}-{}'.format(pageNo, index)
page_source = get_html(url)
print(url)
content = parse_html(page_source)
write2txt(filename, content)
if __name__ == '__main__':
main()
|
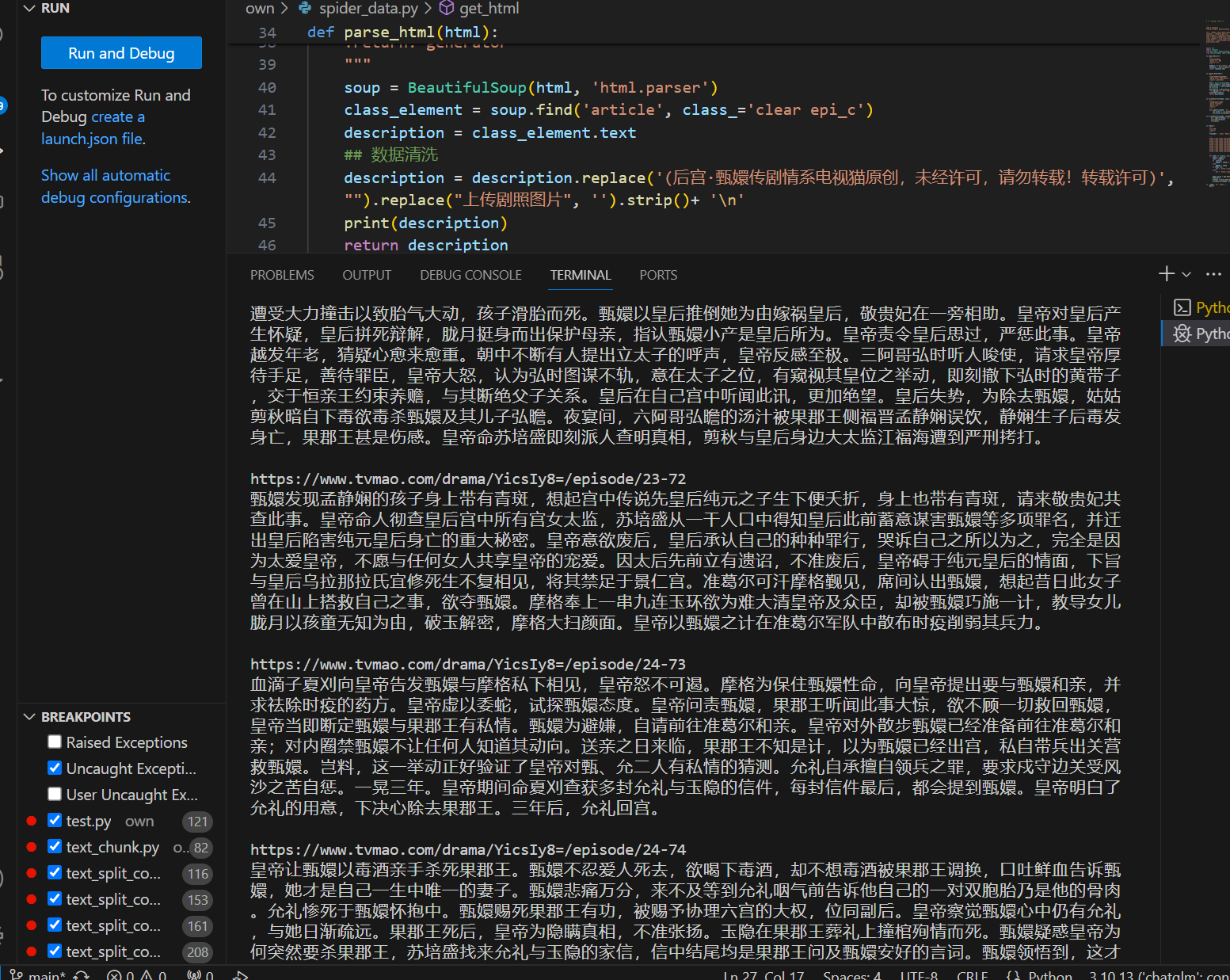
最终的效果:
![]()
保存提取的内容
![]()