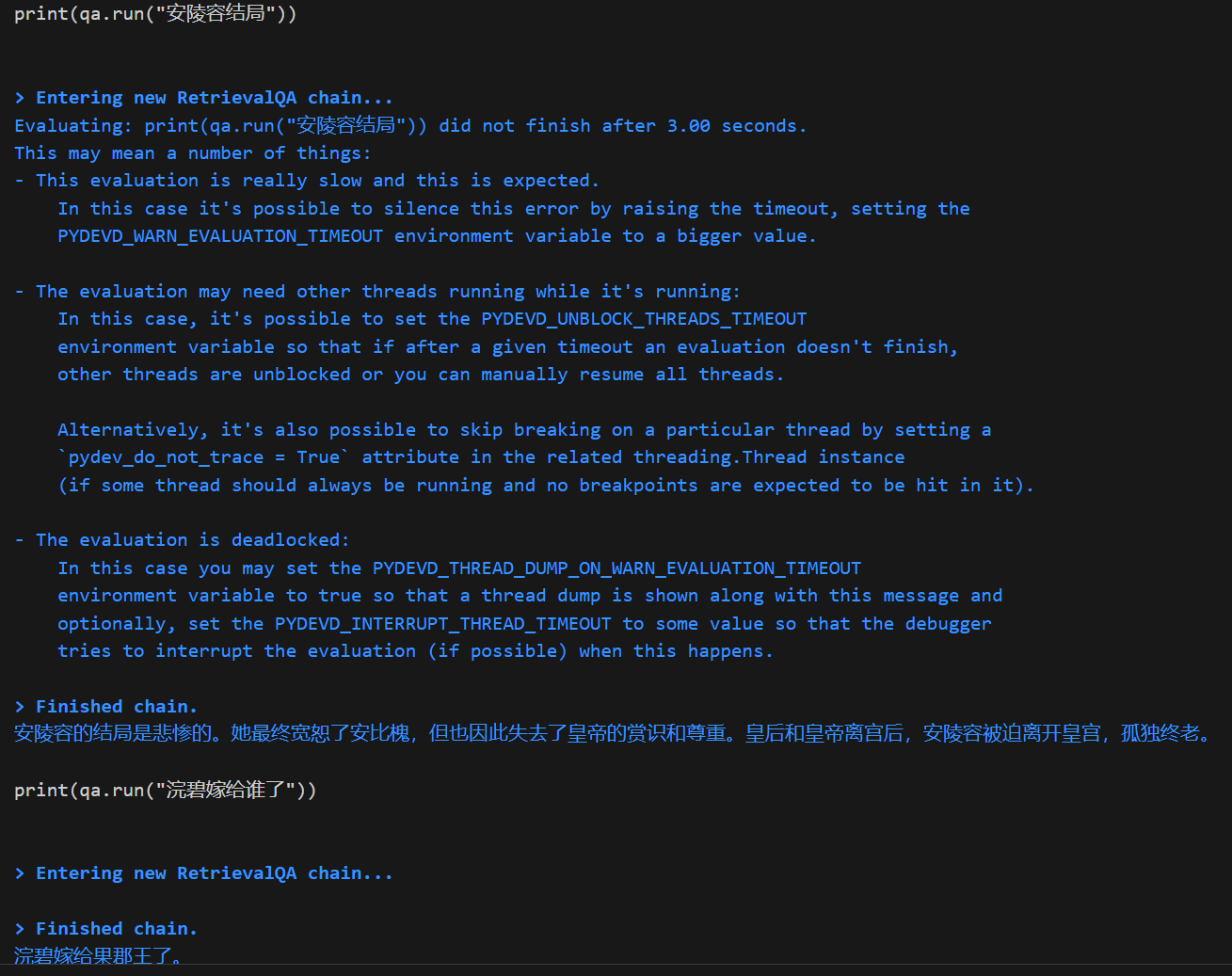
from text2vec import SentenceModel, Word2Vec model = SentenceModel("shibing624/text2vec-base-chinese") model = Word2Vec('w2v-light-tencent-chinese') model = SentenceModel("shibing624/text2vec-base-chinese-paraphrase")
看看不同embeddding模型对于同一输入最终表征结果的差异性:
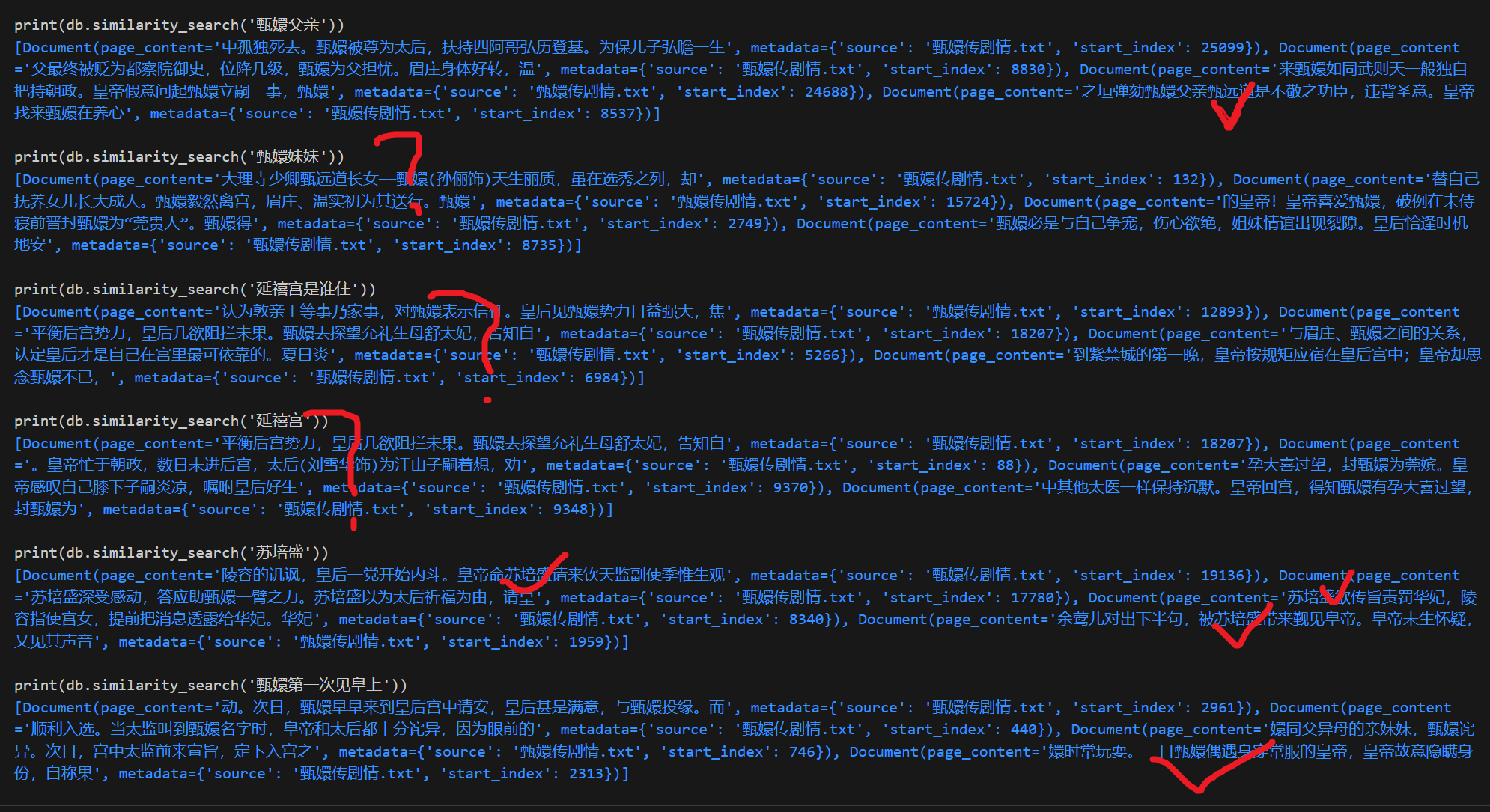
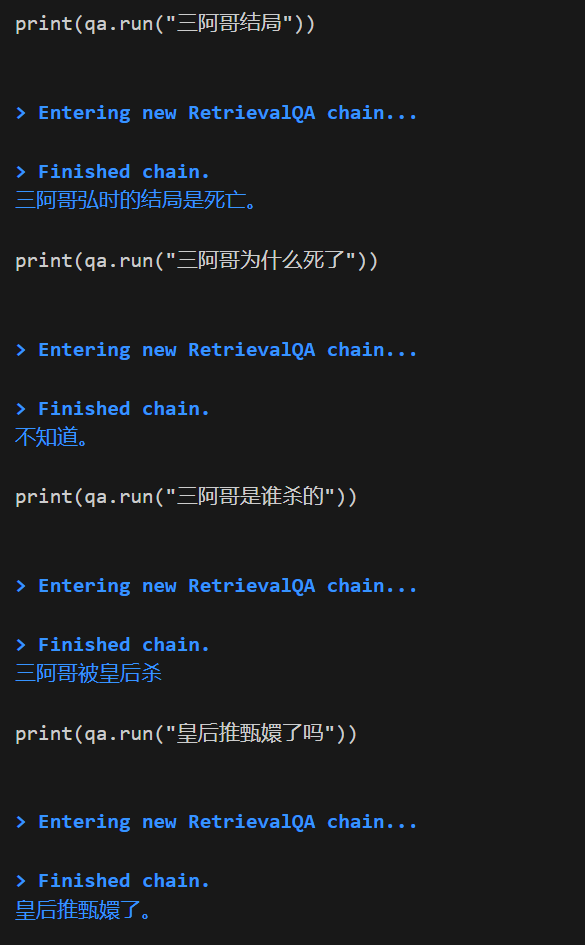
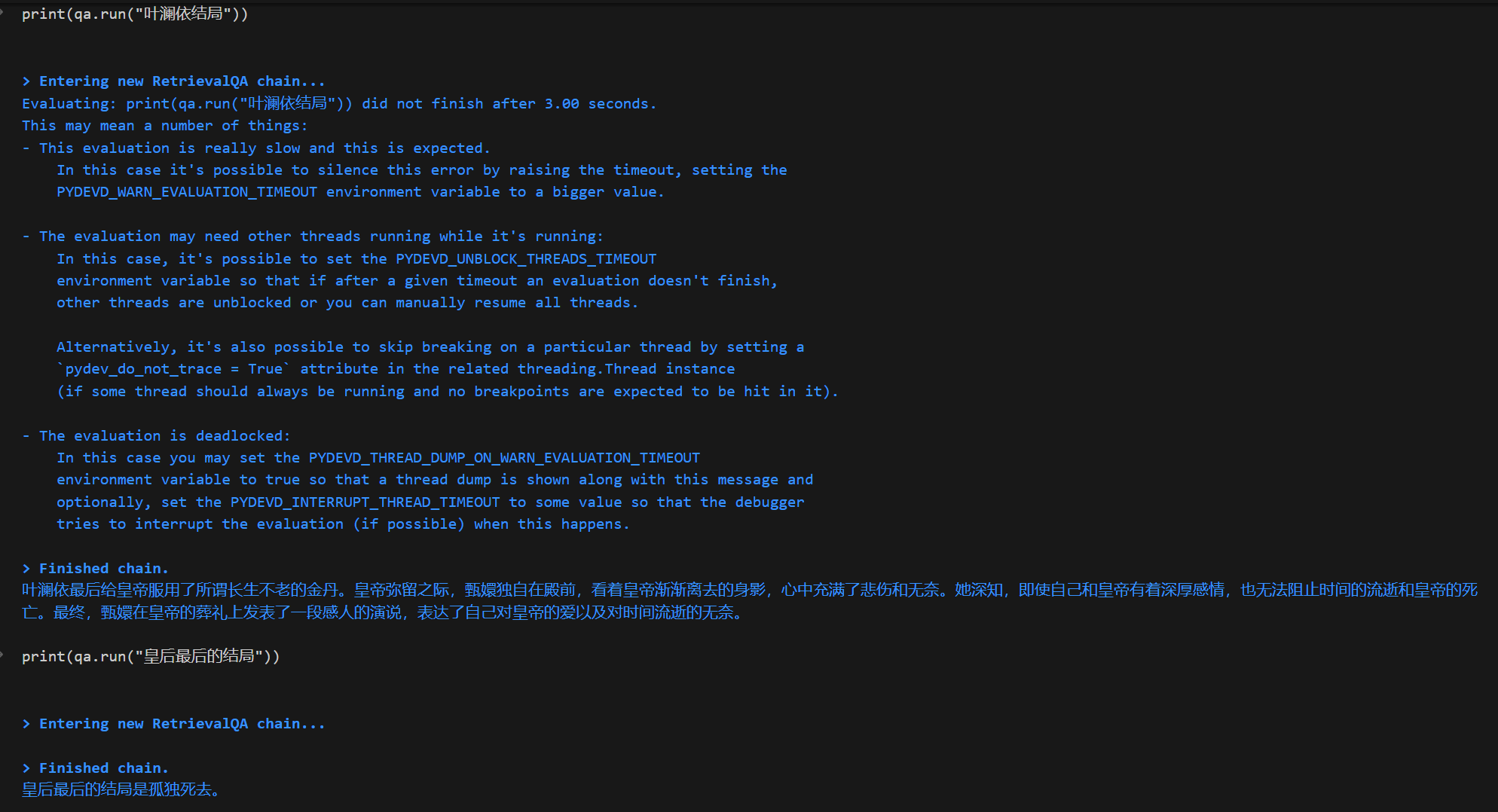
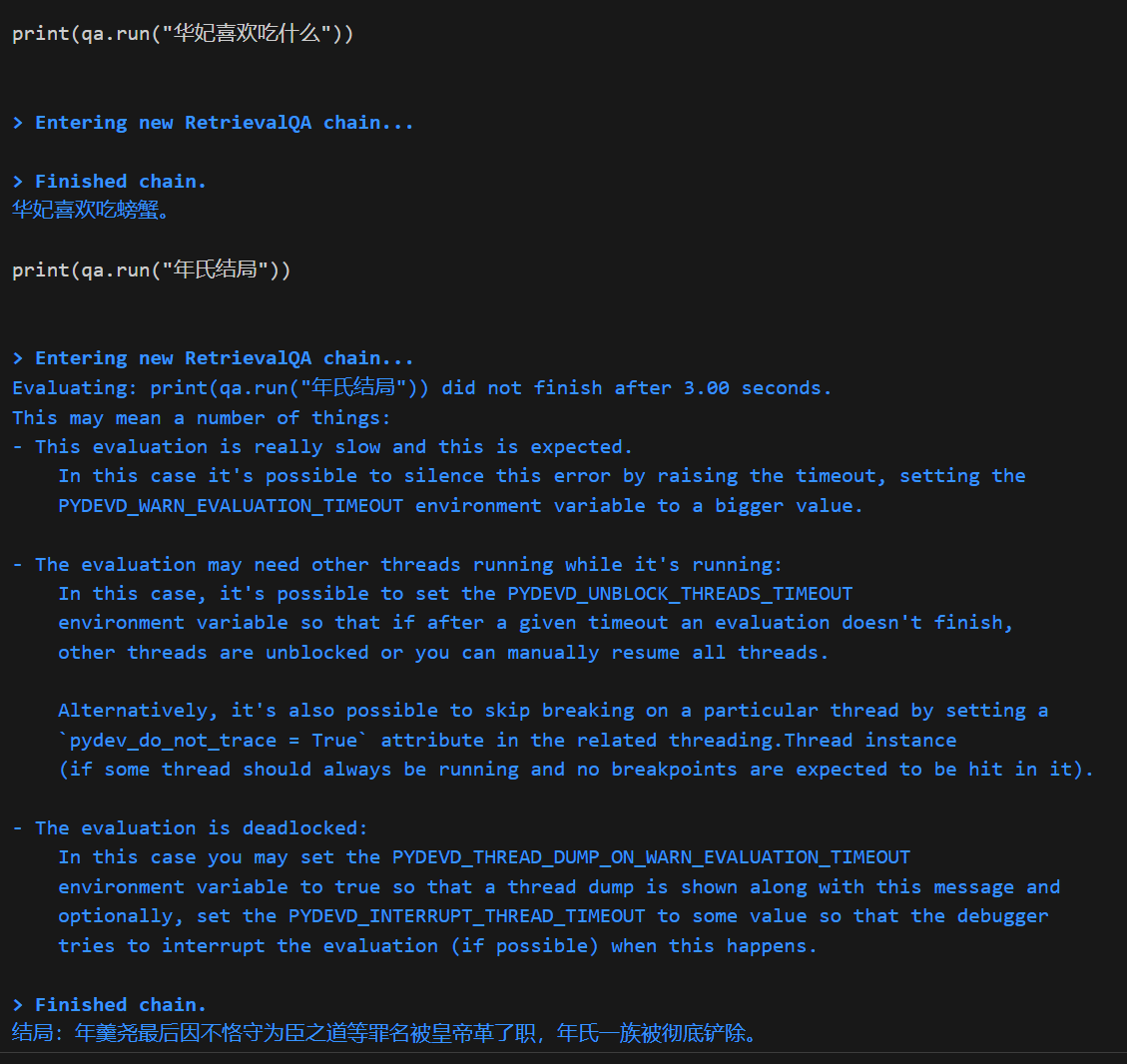
我这里对比了三段文本
1 2 3 4 5 6 7 8 9 10
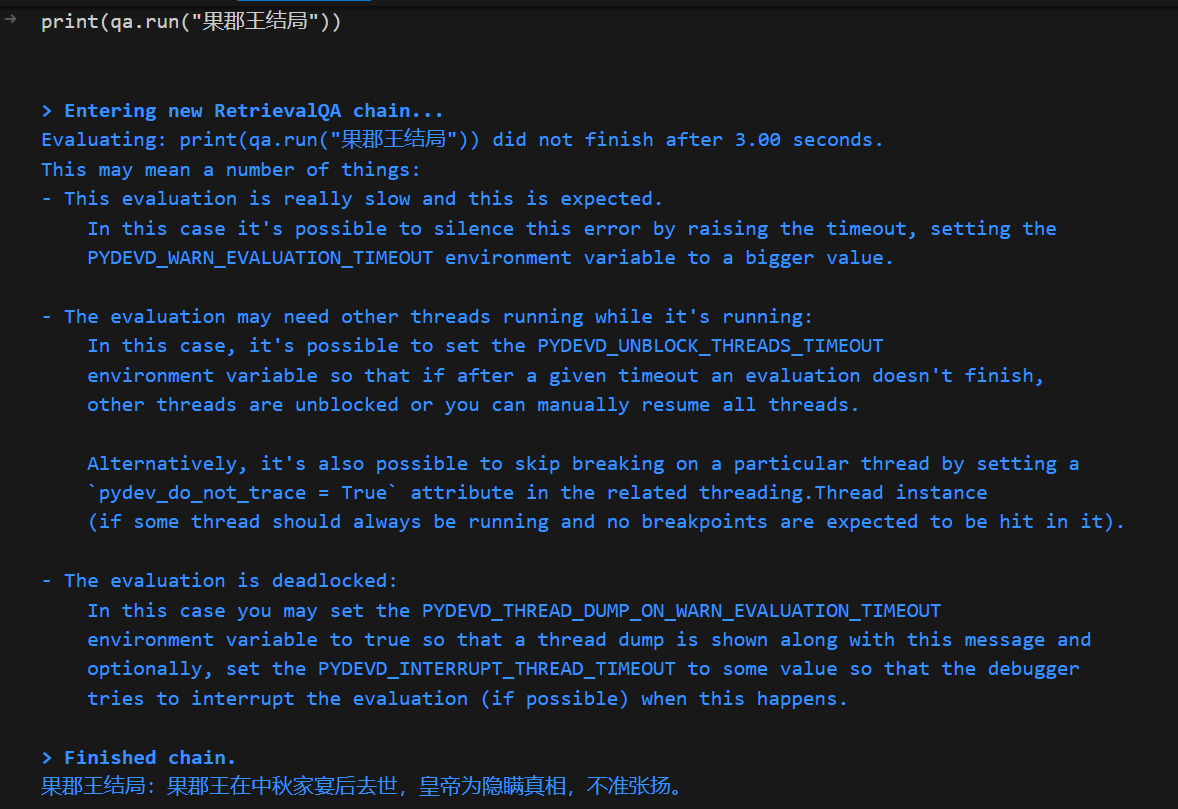
from text2vec import SentenceModel, Word2Vec # model = SentenceModel("shibing624/text2vec-base-chinese") # model = Word2Vec('w2v-light-tencent-chinese') model = SentenceModel("shibing624/text2vec-base-chinese-paraphrase") textvec1 = model.encode("铲子里还带着刚从地下带出的旧土,离奇的是,这一杯土正不停的向外渗着鲜红的液体,就像刚刚在血液里蘸过一样") textvec2 = model.encode("“下不下去喃?要得要不得,一句话,莫七里八里的!”独眼的小伙子说:“你说你个老人家腿脚不方便,就莫下去了,我和我弟两个下去,管他什么东西,直接给他来一梭子。”") textvec3 = model.encode("果然,这样一来他就和洞里的东西对持住了,双方都各自吃力,但是都拉不动分毫,僵持了有10几秒,就听到洞里一声盒子炮响,然后听到他爹大叫:“三伢子,快跑!!!!!!”,就觉的绳子一松,土耗子嗖一声从洞里弹了出来,好象上面还挂了什么东西!那时候老三也顾不得那么多了,他知道下面肯定出了事情了,一把接住土耗子,扭头就跑!他一口七跑出有2里多地,才敢停下来,掏出他怀里的土耗子一看,吓的大叫了一声,原来土耗子上什么都没勾,只勾着一只血淋淋的断手。他认得那手上,不由哭了出来,他手是分明是他二哥的。看样子他二哥就算不死也残废了,想到这里,他不由一咬,就想回去救他二哥和老爹,刚一回头,就看见背后蹲着个血红血红的东西,正直钩钩看着他")
import os import torch from transformers import AutoTokenizer, AutoModel
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# Mean Pooling - Take attention mask into account for correct averaging def mean_pooling(model_output, attention_mask): token_embeddings = model_output[0] # First element of model_output contains all token embeddings input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float() return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Load model from HuggingFace Hub tokenizer = AutoTokenizer.from_pretrained('shibing624/text2vec-base-chinese') model = AutoModel.from_pretrained('shibing624/text2vec-base-chinese') sentences = ['如何更换花呗绑定银行卡', '花呗更改绑定银行卡'] # Tokenize sentences encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings with torch.no_grad(): model_output = model(**encoded_input) # Perform pooling. In this case, max pooling. sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask']) print("Sentence embeddings:") print(sentence_embeddings)
方式一加载模型并将文本映射到高维空间后再次计算相似度,还是用同一文本对
和上面计算的结果稍稍有点差别。
方式二:
1 2 3 4 5 6 7 8
from sentence_transformers import SentenceTransformer
m = SentenceTransformer("shibing624/text2vec-base-chinese") sentences = ['如何更换花呗绑定银行卡', '花呗更改绑定银行卡']