经过前面的指导我们安装好环境后,现在就准备训练我自己的数据集的SSD模型,这里我跟TensorRT的例子保持一致,都用TensorFlow Object Detection API训练获取模型。那么开始详细介绍TensorFlow Object Detection API的安装以及SSD inception V2训练我自己的数据集。
首先新建一个名为TensorFlow文件夹
然后定位到该文件夹内
1 | cd TensorFlow |
下载TensorFlow Models
1 | git clone https://github.com/tensorflow/models.git |
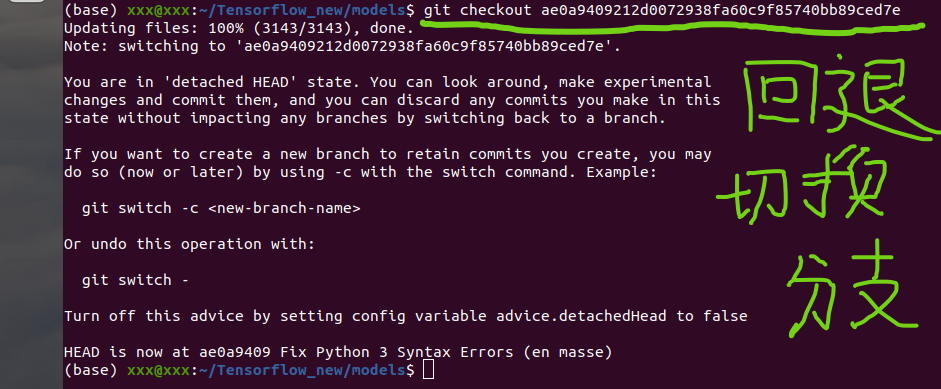
切换分支方法
1 | git checkout ae0a9409212d0072938fa60c9f85740bb89ced7e |
到现在TensorFlow形式如下:
1 | TensorFlow |
安装Protobuf
1 | pip install protobuf |
安装依赖包
1 | # From within TensorFlow/models/research/ |
添加research/slim 到PYTHONPATH
1 | gedit ~/.bashrc |
至此环境变量起作用了
安装COCO API
1 | cd Tensorflow/models/research |
验证安装是否成功
1 | cd TensorFlow\models\research\object_detection |
运行object_detection_tutorial.ipynb
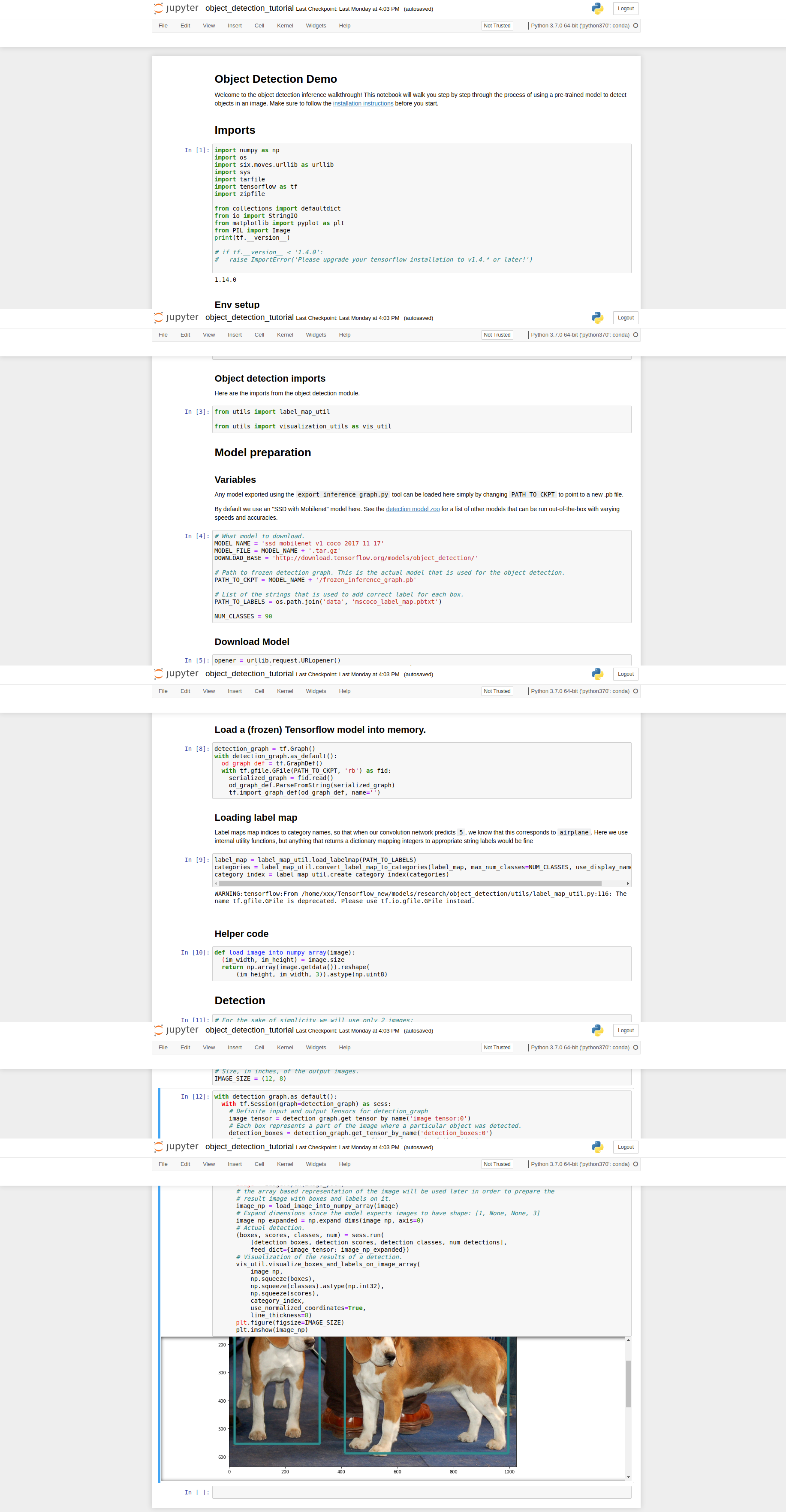
运行无误说明安装成功。
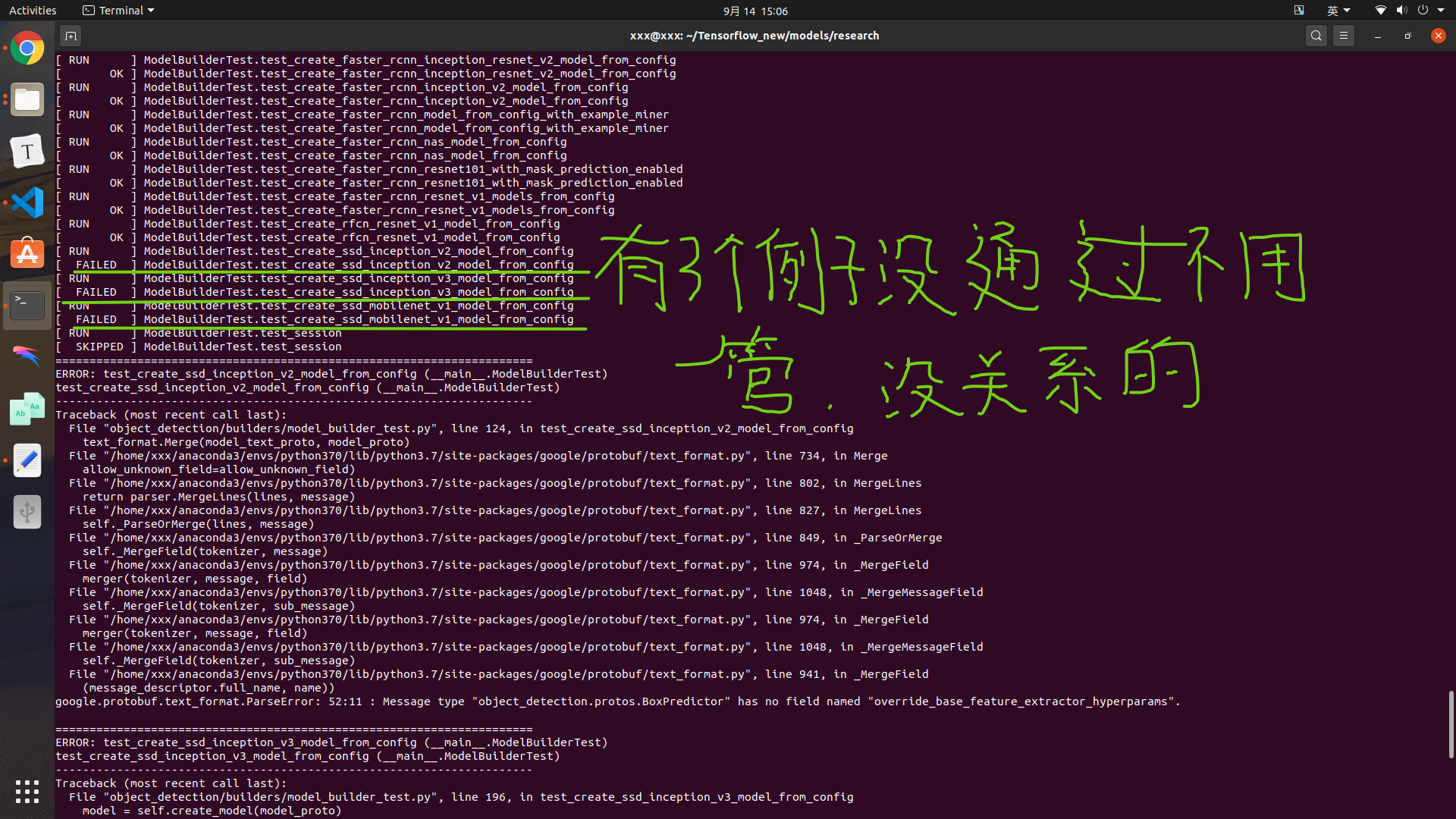
这里说明一点,如果你要运行model_builder_test,可能会出现有些例子运行失败,这里不用care这些失败,无视就好了,不影响接下来的训练。
1 | python object_detection/builders/model_builder_test.py |
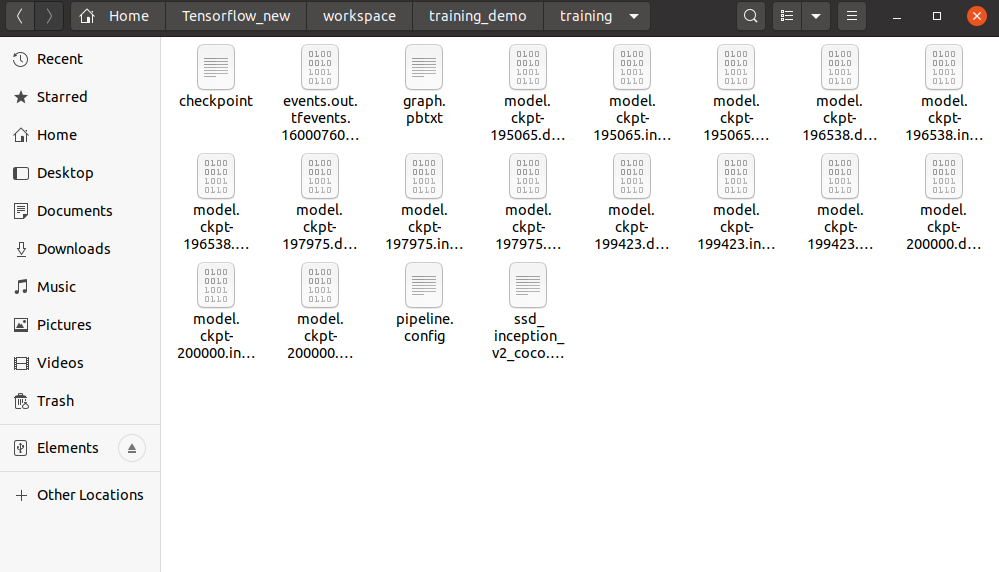
首先,在TensorFlow下新建workspace/training_demo文件夹
1 | TensorFlow |
至于training_demo下的内容不需要新建,根据下面的步骤需要什么补充什么就行。
images是用来保存你的原始数据图像样本与注释文件的,现在要将其分类train和test,可以通过以下代码实现,9:1的比例也可以根据自身需要进行更改。
1 | """ usage: partition_dataset.py [-h] [-i IMAGEDIR] [-o OUTPUTDIR] [-r RATIO] [-x] |
1 | python partition_dataser.py -x -i training_demo\images -r 0.1 |
创建标签文件
1 | item { |
生成TensorFlow Records
在TensorFlow下新建scripts\preprocessing文件夹
xml 转 csv
1 | """ |
1 | cd TensorFlow/scripts/preprocessing |
csv 转 record
1 | """ |
1 | cd TensorFlow\scripts\preprocessing |
之后会在training_demo/annotations文件夹下生成test.record 和 train.record 即为转换成功。
创建训练Pipeline
首先下载预训练模型选择ssd_inception_v2_coco下载
将下载好的模型解压到 pre-trained-models
1 | training_demo/ |
创建pipeline.config
1.复制training_demo/pre-trained-models/ssd_inception_v2_coco_2018_01_28/pipeline.config到training_demo/training
2.打开training_demo/training下的 pipeline.config ;
1 | # SSD with Inception v2 configuration for MSCOCO Dataset. |
开始训练
1.复制TensorFlow/models/research/object_detection/train.py到training_demo文件夹
2.cd training_demo, 运行
1 | python train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/pipeline.config |
最终在training文件夹保存到训练所得到的模型。